-
인공지능, 훈민정음에 스며들다 - 대화요약머신러닝 2022. 1. 23. 17:17

길고 긴 2달 하고도 2주간의 해커톤 대회가 끝이났다.
참 다양한 상황을 겪었고, 많은 것을 느끼게 해준 대회였다.
대회를 하면서 가장 다짐했던건 '기록'에 대한 생각이었다. 나는 나름대로 매년 해커톤을 참가하면서 실력을 키워나갔던 것 같다.
하지만, 대회가 끝나고 방전이 된 나머지 해커톤을 하면서 배웠던 지식, 느낌 감정들을 정리하지 않았다. 이번 대회를 하면서 우연히 과거에 내가 참가했던 대회들에 대한 후기들을 읽게 되었다. 그 후기들을 보면서 잊고 있었던 기억들이 흐리게나마 떠올랐다. '나도 참 얻어간게 많았는데, 정리한게 없구나' 라는 생각이 들었다. 그래서 이번에는 늦게나마 내가 실험한 모델, 아이디어, 아쉬운점을 정리해보려한다.
1. 주제
한국어 메신저 대화를 요약하자.
- 데이터
- AI-hub 에서 제공하는 총 N개 카테고리로 분류되어있는 메신저 대화 내용
- 메신저 대화 내용인만큼 오타, 신조어, 비속어 등 매우 많음.
- Metric
- Rouge-L(제1지표)
- Rouge-2(제2지표)
- Rouge-1(제3지표)
- 리더보드에는 Rouge-L만 적용
- 제약사항
- pretrained model 사용 금지 (--> scratch only 사용)
2. 사용한 모델 ( KOBART)
Bidirectional Transformers(BERT)에 Auto-Regressive Transformers(GPT)를 결합한 seq2seq 구조의 denosing autoencoder 모델. 여러 엔드 태스크에 응용성이 높음

- 인코더 입력을 디코더 출력과 align 할 필요가 없으므로 임의의 noise transformation을 허용
- 왼쪽의 손상된 (masking) 문서는 bidirectional model로 인코딩 되고, 그 다음 오른쪽 원본 문서로의 likelihood는 autoregressive decoder로 인해 계산됨
- Fine-tuning 시에 원본 문서가 encoder와 decoder에 모두 입력되며, 우리는 decoder의 마지막 hidden state로부터 얻은 representation을 사용한다.
- Model Architecture
- seq2seq 트랜스포머 구조를 사용
- activation function ReLU → GeLUs
- Base model은 6 layer, Large model은 12 layer를 사용
- BERT와의 주요한 차이
- 디코더의 각 레이어에서 인코더의 마지막 hidden layer 이후 cross-attention을 추가 실행
- BERT와는 달리 word prediction을 위해 FFN을 추가하지 않음
- 파라미터 10% 정도 많음
3. 다양한 아이디어들
- PLM (Pretrained language model)
- Scratch model을 학습시켜야하는 대회의 특성상 1) pretrained model, 2) finetuning model 순으로 학습하였다.
- 기존의 BART 모델에서는 엄청난 양의 데이터를 self-supervised learning 방식으로 pretrain하였다.
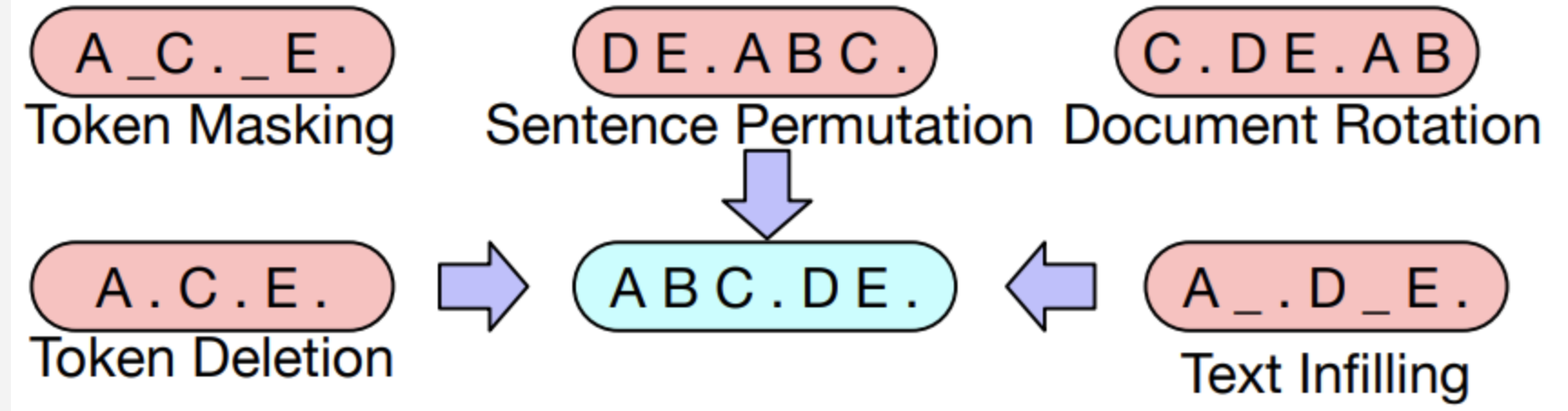
- Token Masking: BERT처럼 랜덤 토큰을 masking하고 이를 복구하는 방식이다.
- Token Deletion: 랜덤 토큰을 삭제하고 이를 복구하는 방식이다. Masking과의 차이점은 어떤 위치의 토큰이 지워졌는지 알 수 없다는 점이다.
- Text Infilling: 포아송 분포를 따르는 길이의 text span을 생성해서 이를 하나의 mask 토큰으로 masking 한다. 즉 여러 토큰이 하나의 mask 토큰으로 바뀔 수 있고 길이가 0인 경우에는 mask 토큰만 추가될 수도 있다. SpanBERT에서 아이디어를 얻었는데 SpanBERT는 span의 길이를 알려주었으나 여기서는 알려주지 않고 모델이 얼마나 많은 토큰이 빠졌는지 예측하게 한다.
- Sentence Permutaion: Document를 문장 단위로 나눠서 섞는 방법이다.
- Document Rotation: 토큰 하나를 정해서 문장이 그 토큰부터 시작하게 한다. 모델이 document의 시작을 구분하게 한다.
- 그중에 우리는 가장 간단하고도, 무한히 pretrained 시킬 수 있는 'Text Infilling'를 활용해 데이터를 충분히 학습시켰다.
- 참고 :https://arxiv.org/pdf/2004.10964.pdf
- Data Augmentation
- 우리는 한정된 데이터 다양한 방법으로 증가시켰다.
- 랜덤으로 선별된 발화만 선택된 데이터
- 가장 길게 발화한 부분만 선택된 데이터
- 발화의 순서를 랜덤으로 변경한 데이터
- 일부 단어를 소리나는대로 변경한 데이터 (G2pk를 사용 --> 시간이 너무 걸려서 drop)
- 이와 같은 방법으로 우리는 무한하게 data augment 를 진행했다. data augment를 통해 약 0.01 score의 향상을 보였다.
- Data preprocessing
- 허깅페이스의 pretrained tokenizer 이용 : PreTrainedTokenizerFast.from_pretrained("hyunwoongko/kobart")
- 다양한 tokenizer를 사용해봤으나 큰 차이가 없었다.
- soynlp 이용해서 repeat word (2개 이상)
- ㅋㅋㅋㅋㅋ 과 같은 발화를 일관성 있게 변경하였다.
- Category Fine tuning
- 데이터가 9개의 대화 주제로 구분되어있었다. 우리는 각 주제별로 자주 사용하는 단어, 대화체 등이 상이한 것을 발견하고 충분히 학습된 모델을 각 카테고리별로 15epoch씩 finetuning하였다.
- 기존 전체데이터를 한번에 학습한 것보다 0.015 score 향상을 보였다.
- Inference tuning
- 대화 생성을 위한 파라미터를 조절하며 실험하였다.
- Model training method
- 가장 아쉬운 부분이다. papers with codes 에서 다양한 모델 학습 방법이 단일 모델의 성능을 향상시킴을 확인했다.
- R-drop
- 같은 2개 모델의 학습분포가 차이가 없도록 학습하는 방식이 모델 학습에 도움을 준다.
- 코드가 전혀 학습이 되지 않았음. ㅠㅠ (왜인지 원인파악은 못함ㅠ.ㅠ)
4. 뜻밖의 배움
- 큰 모델이 가장 좋은 모델이다(?) --> X
- 데이터의 량에 따라 큰모델은 심한 overfitting의 문제를 가질 수 있다.
- Collate function
- Deepspeed의 활용
- Config의 중요중요중요성!!
- Pytorch lightning
- Scratch model learning
- scratch model을 학습할 때, '잘 되는것으로 알려져 있'는 setting 들이 어느정도 존재하는 것같다.
- 내가 배운 것들은
bias 에는 weight decay를 주지 않는 것이 좋다.scheduler 는 consine warmup scheduler로- 이런것들은.. 카더라라서, 근거는 전혀없다. 좀더 공부할 필요가 있겠다.
5. 아쉬운 점
- 체력적 한계로 인한 빠르지 못한 실행력이 제일 아쉽다. ㅠ
- 관련한 SOTA논문들을 빠르게 읽어보고, 실행에 옮기지 못했다. --> 막판에 시간이 모자란채로 진행한게 아쉬웠다.
6. 어째튼 결과
- 본선 8위로 마무리했다.
- 너무 아쉽다. 회사를 다니며 진행하니 중간에 멘탈도 많이 흔들리고, 지쳤다... ㅠ 아 근데 너무 많이 배우고, 깨닫는 시간이었다. 이런 자극 많이 만들어야지..!!
'머신러닝' 카테고리의 다른 글
[ML] GBM (Gradient Boosting machine) (0) 2021.05.19 [부캠] Python 특징에 대한 개념 정리 (0) 2021.01.18 앙상블 기법 배깅 vs 부스팅 vs 스태킹 (0) 2021.01.15 [머신러닝]샘플링 기법 (0) 2020.12.07 [Pytorch] multiple forward process (0) 2020.06.12