-
[부캠] CNN 파헤치기AI 부캠 2021. 2. 4. 13:49
- Convolution Neural Network (CNN)
- Pretrained CNN
- Segmentation
- Object detection
- 실습
Convolution Neural Network (CNN)
Convolution
커널을 이동시키며 Input을 선형모델과 합성시키는 구조.
변환에 이용되는 parameter 수가 적다는 특징이 있다.
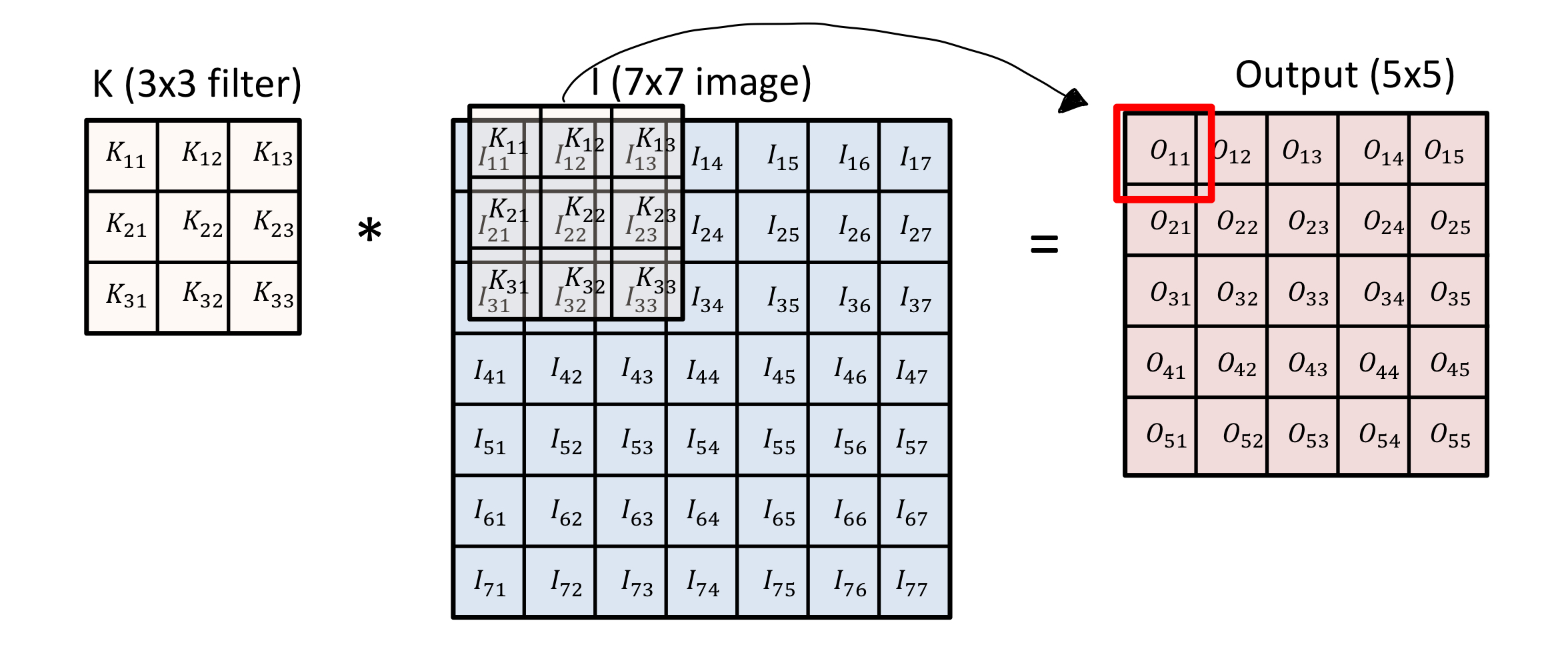
예시
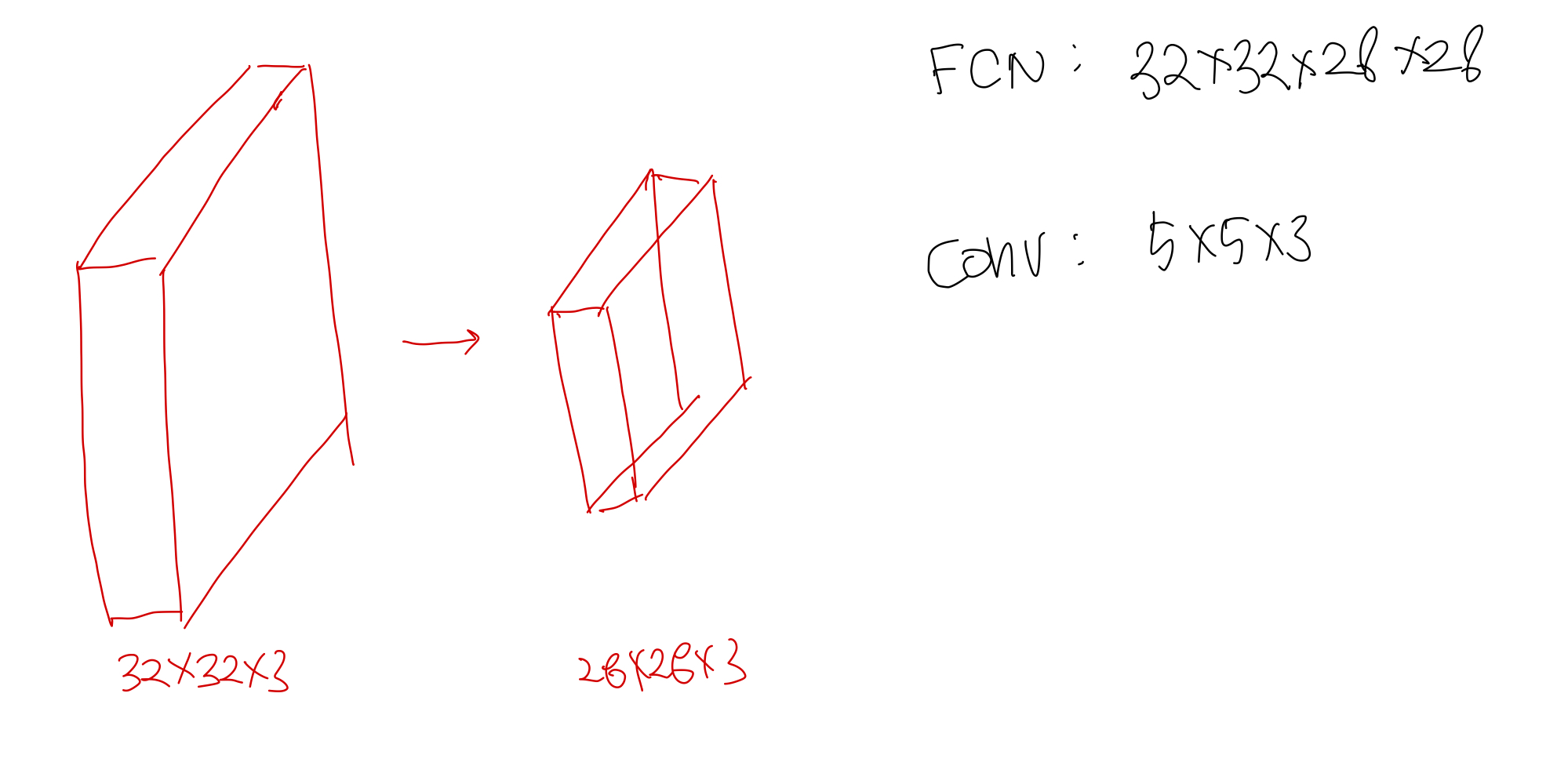
32*32*3 --> 28*28*4로 변환시키기위해
4*5*5*3 사이즈의 kernel만 있으면 가능하다.
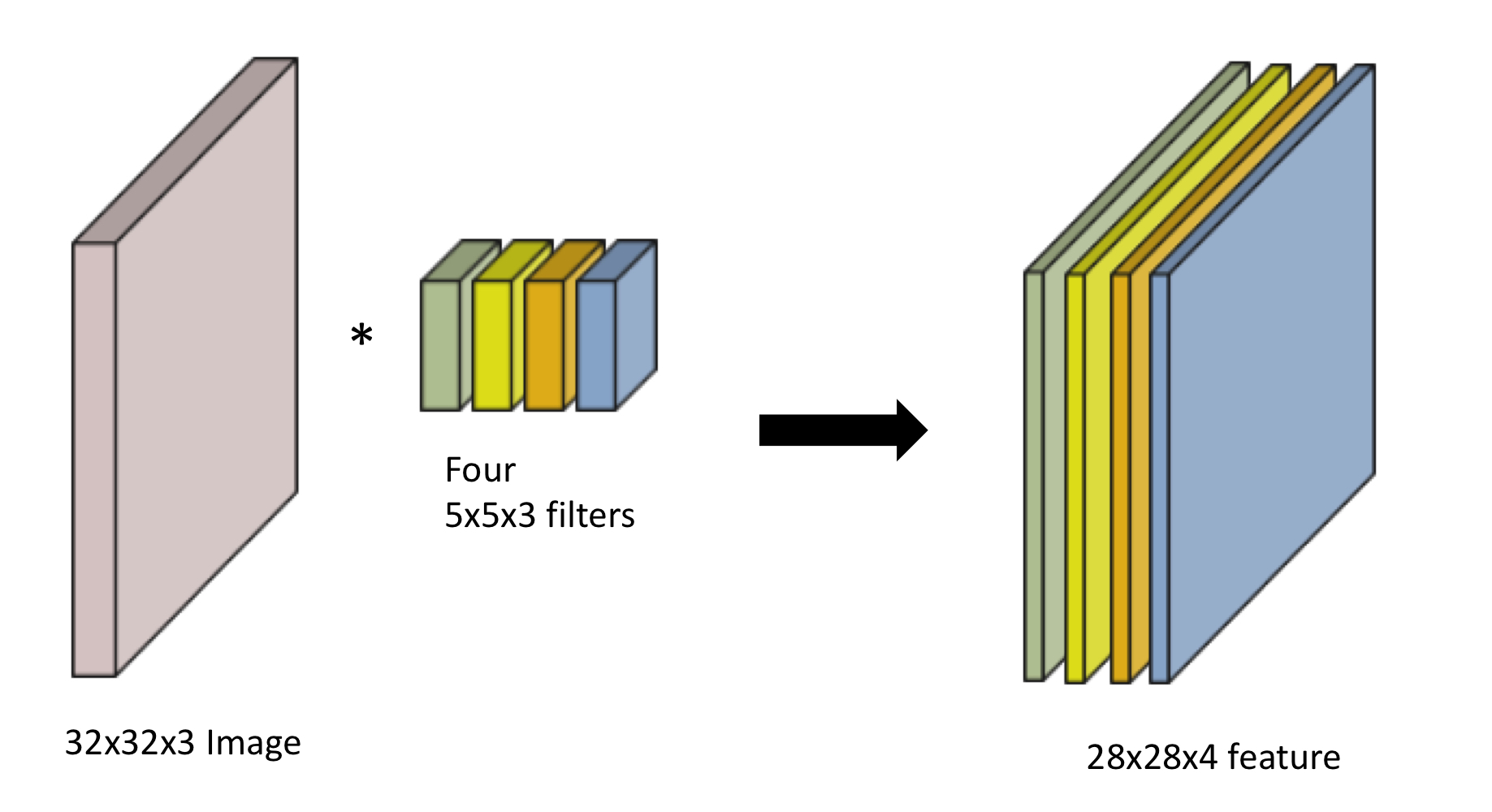
Convolution Neural Network (CNN)
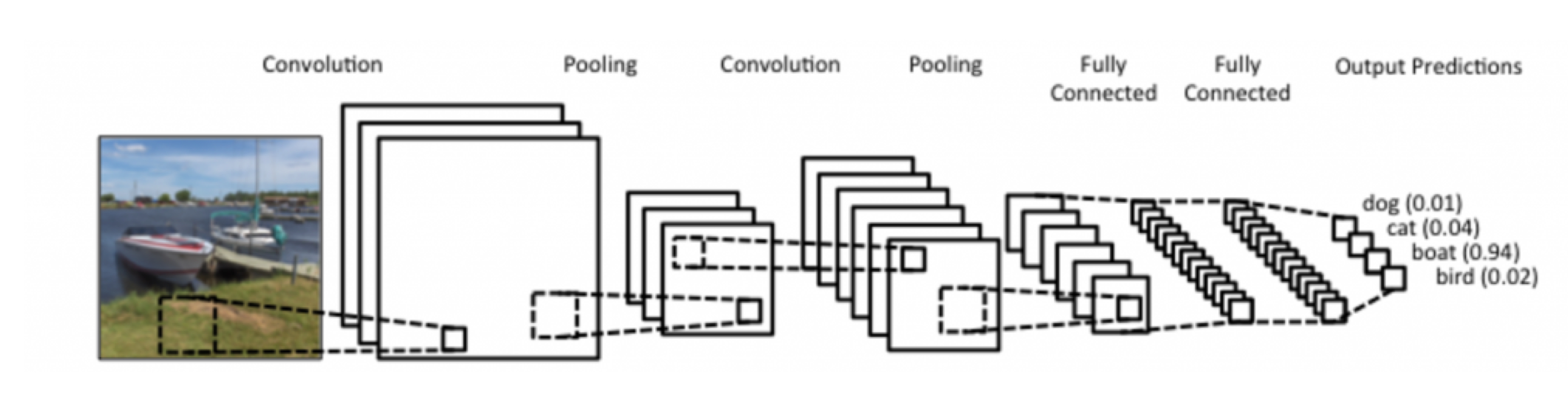
CNN은 주로 convolution layer, pooling layer, fully connected layer 로 구성되어있다.
Convolution & pooling layer : features extraction으로 사용
Fully connected layer : decision makeing 으로 사용
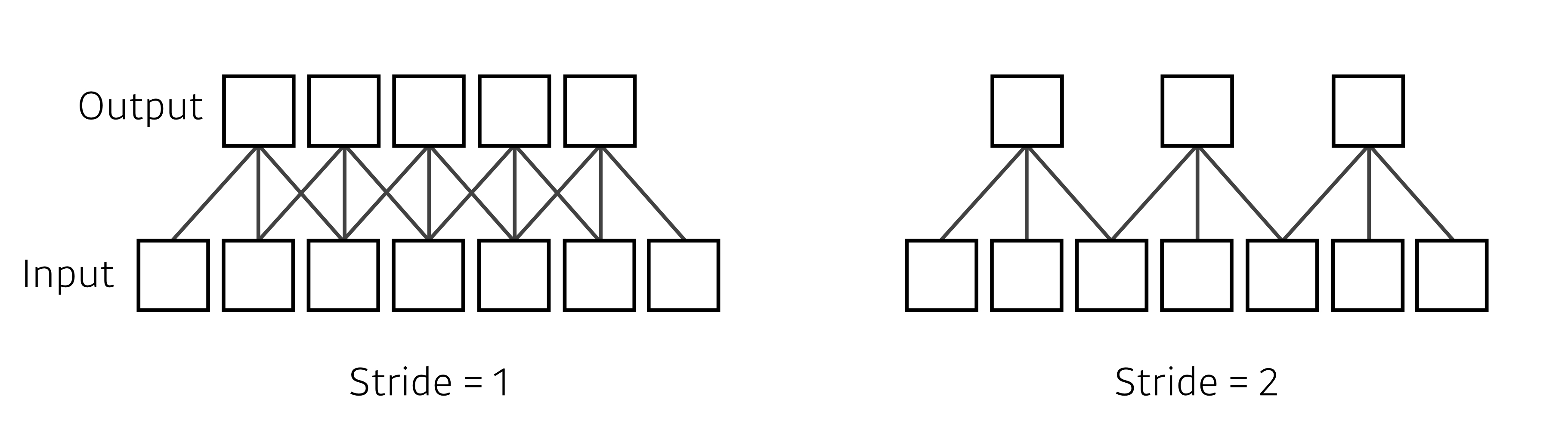
Stride
입력데이터에 필터를 적용할 때 커널이 이동할 간격.
O : ouput size H : input size P : padding size K : kernel size S : stride size
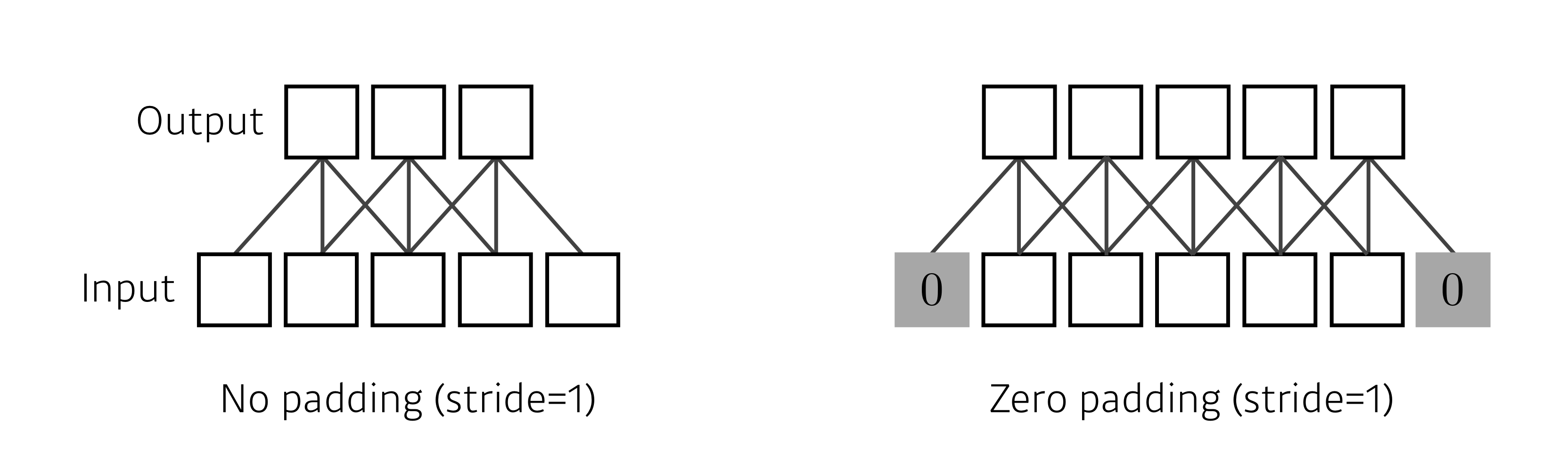
Padding
입력데이터 주변을 특정 값(기본값 0 )으로 채워 늘리는 것. 출력 데이터의 공간적 크기를 조절하기 위해 사용된다.
Pooling
convolution layer을 resizing하여 새로운 layer를 얻는 것
커널과 비슷한 역할, 단 input layer의 사이즈를 줄이기위해 사용이된다.
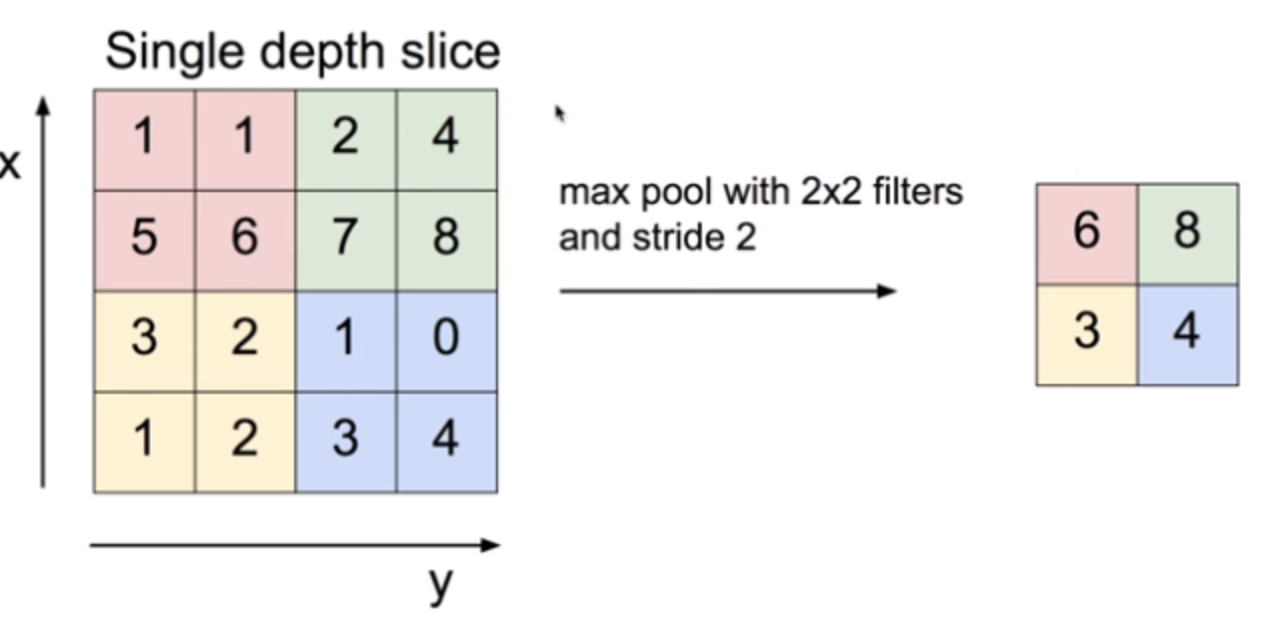
max pooling
커널의 영역에서 최댓값을 반영하는 pooling 기법
average pooling
커널의 영역의 평균을 반영하는 pooling 기법
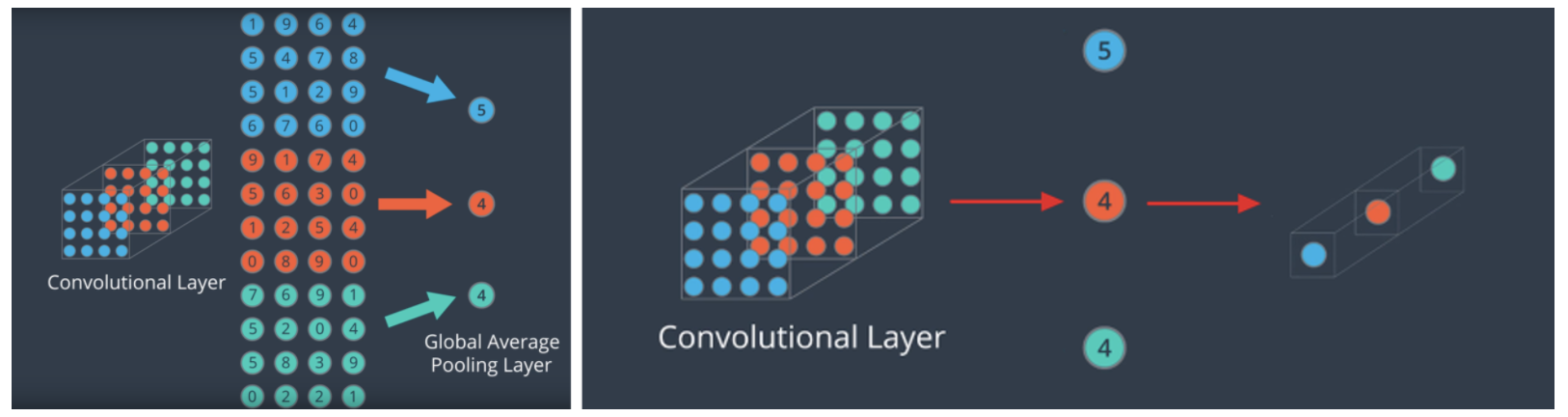
global average/ max pooling
pooling의 역할을 수행하지만, global average / max pooling은 Input vector를 1차원으로 줄인다.
다음 그림과 같이 각 채널들의 W,H를 1로 모두 줄인다.
이러한 방법은 요즘 FCN(fully connected network layer)를 줄이는 방법으로 사용되고 있다고 한다.
Count Parameters
Parameter는 deep learning의 성능을 좌우하는 매우 중요한 부분이다.
특히, convolution layer는 FCN 보다 parameter를 매우 줄이고, 더 깊은 층을 쌓았다는 것에 큰 의의가 있다.
Convolution layer는 Kernel size만큼의 parameter만 필요하다.
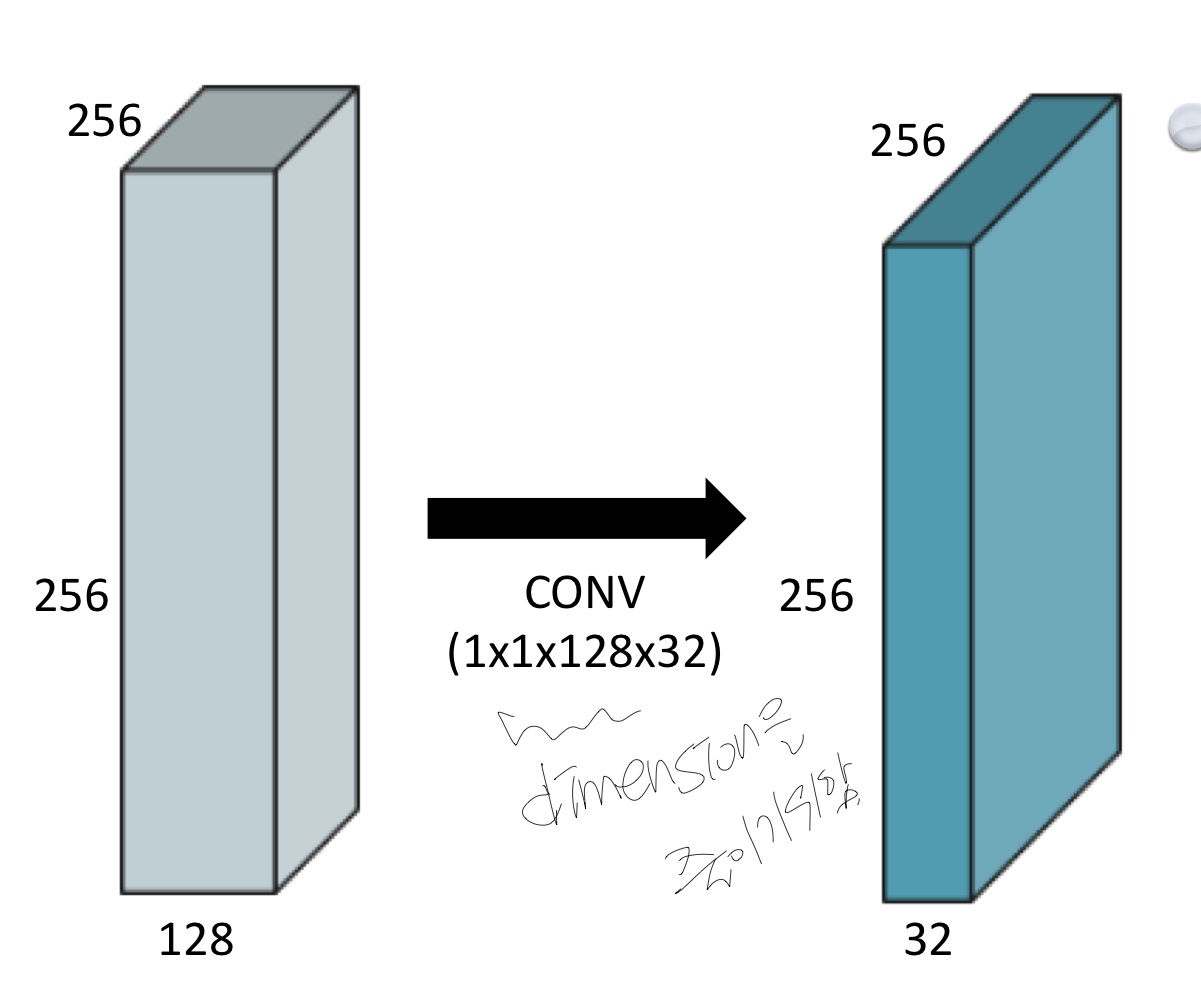
1X1 convolutions
1X1 convolution은 W,H는 고정시킨채 dimension(channel)를 줄이기 위해 활용된다.
Pretrained CNN
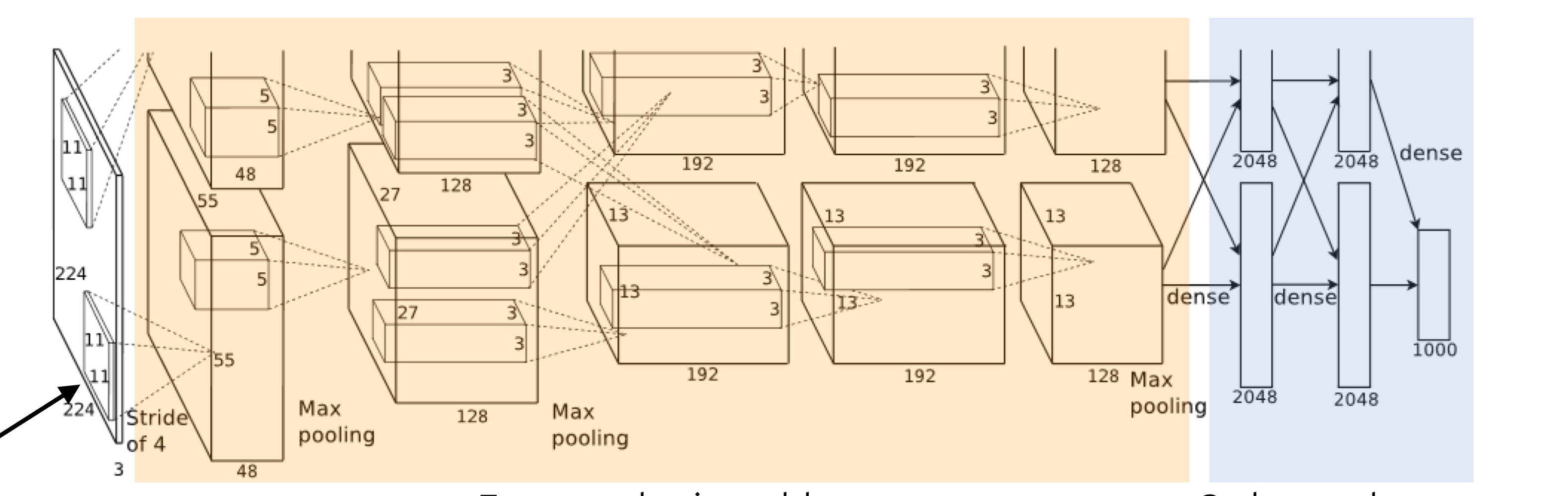
AlexNet
최초 ILSVRC 우승 모델
의의
1. ReLU 를 처음 사용함
-non linear성을 높이고 gradient vanishing 현상을 줄임.
2. Drop out, Data augmentation 이용
class AlexNet(nn.Module): def __init__(self, num_classes=1000): super().__init__() self.net = nn.Sequential( nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4), # (b x 96 x 55 x 55) nn.ReLU(), nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), # section 3.3 nn.MaxPool2d(kernel_size=3, stride=2), # (b x 96 x 27 x 27) ... ) self.classifier = nn.Sequential( nn.Dropout(p=0.5, inplace=True), nn.Linear(in_features=4096, out_features=4096), nn.ReLU(), ... nn.Linear(in_features=4096, out_features=num_classes), ) def forward(self, x): x = self.net(x) x = x.view(-1, 256 * 6 * 6) # reduce the dimensions for linear layer input return self.classifier(x)VGGNet
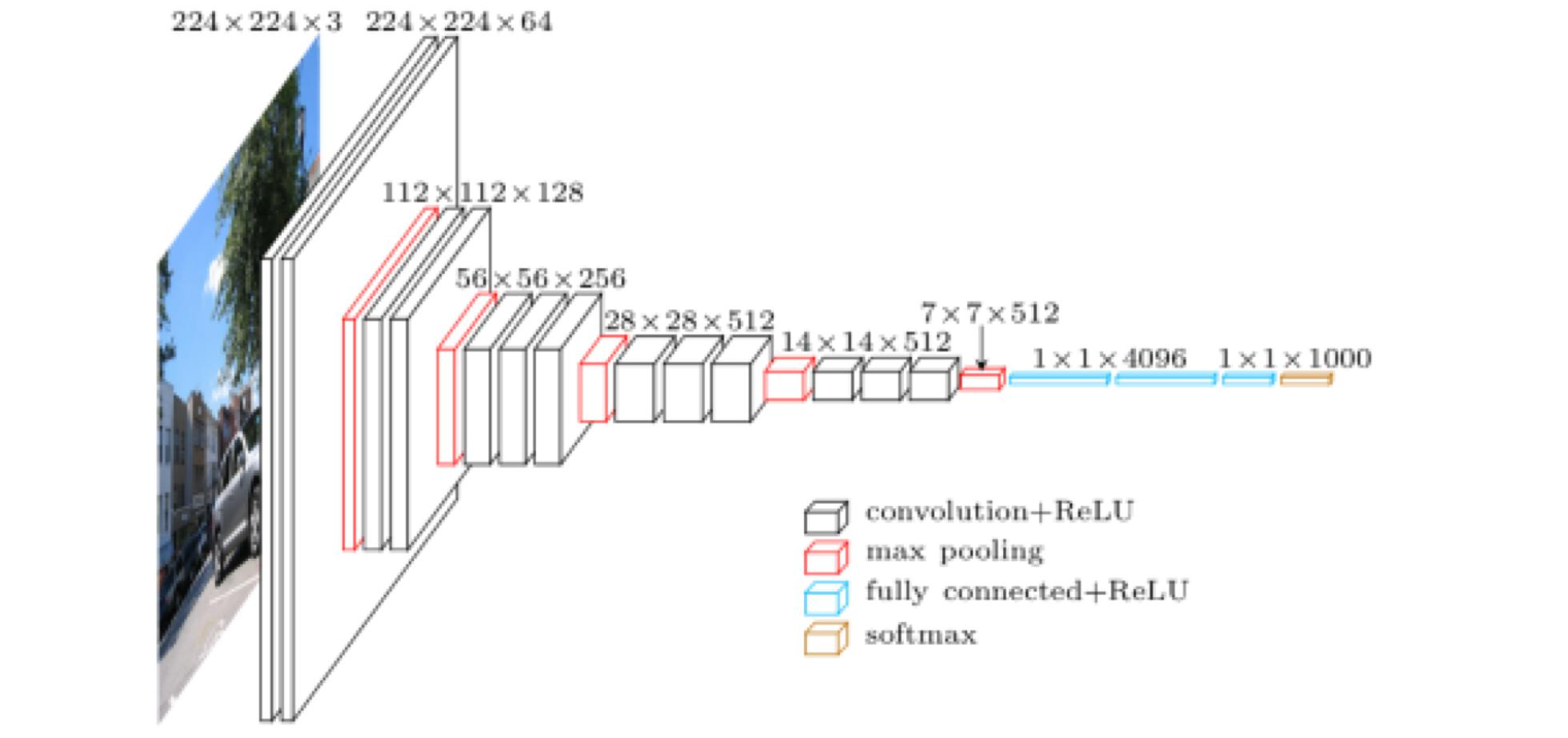
깊이를 더 깊게 만든 모델
의의
1. 3*3 convolution filter를 사용하여 receptive field는 유지하되 parameter 수를 줄임.
2. 1*1 convoltion layer를 사용
class VGG(nn.Module): def __init__(self, features): super(VGG, self).__init__() self.net = nn.Sequential( nn.Conv2d(in_channels = 3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True), nn.MaxPool2d(kernel_size=2, stride=2), nn.Conv2d(in_channels = 64, 128, kernel_size=3, padding=1),# 3*3 kernel nn.ReLU(inplace=True) nn.MaxPool2d(kernel_size=2, stride=2) ... ) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(512, 512), nn.ReLU(True), nn.Dropout(), nn.Linear(512, 512), nn.ReLU(True), nn.Linear(512, 10), ) def forward(self, x): x = self.net(x) x = x.view(x.size(0), -1) x = self.classifier(x) return x** why 3*3 kernel?
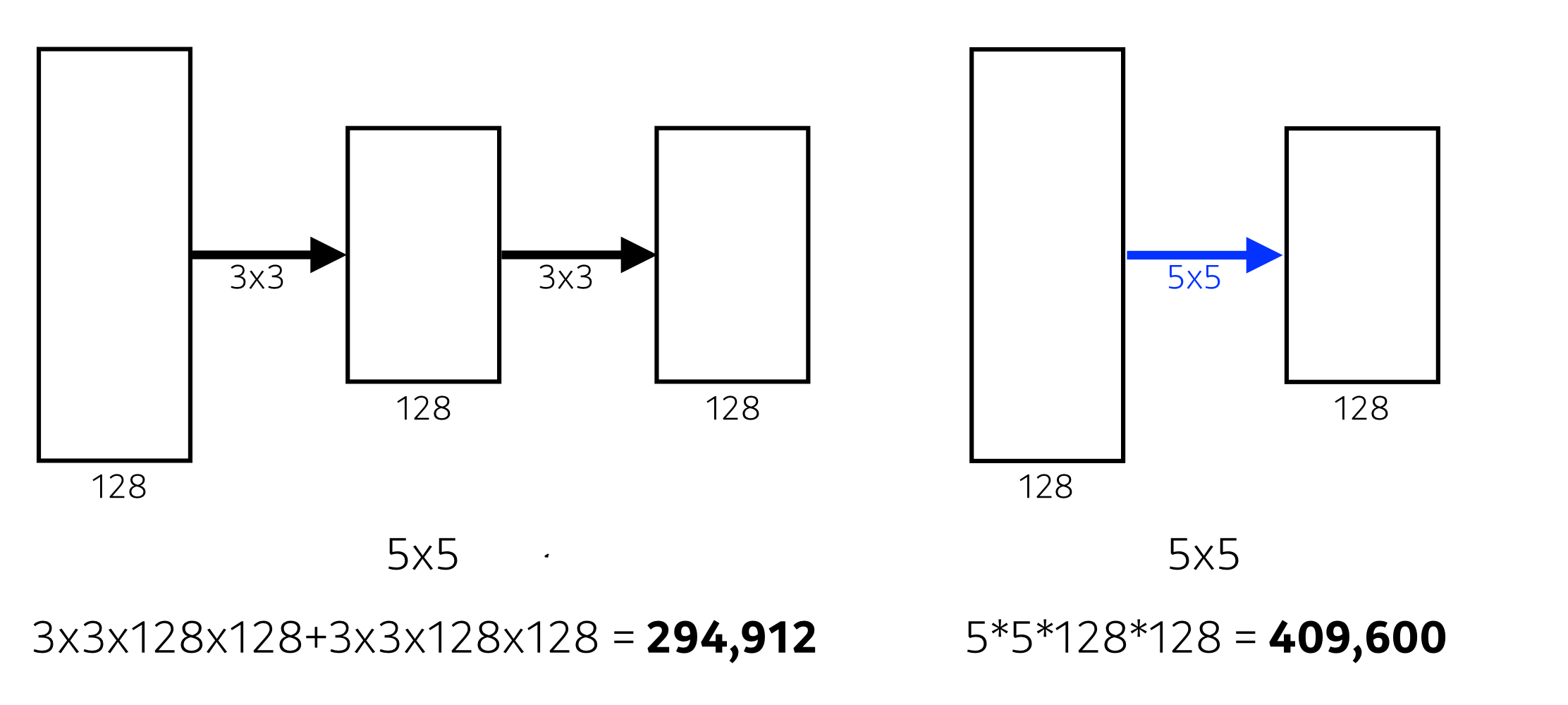
receptive field : conv연산을 통해서나온 node가 input이미지의 어느정도를 커버하는가
3*3 conv layer를 2번 거치면 input 이미지(데이터)의 5*5부분을 한 노드가 커버할 수 있다.
하지만, 한번에 5*5를 사용하는 것보다 param수는 적게 사용한다.
GoogLeNet
NIN(Network in Network) 구조를 활용한 모델
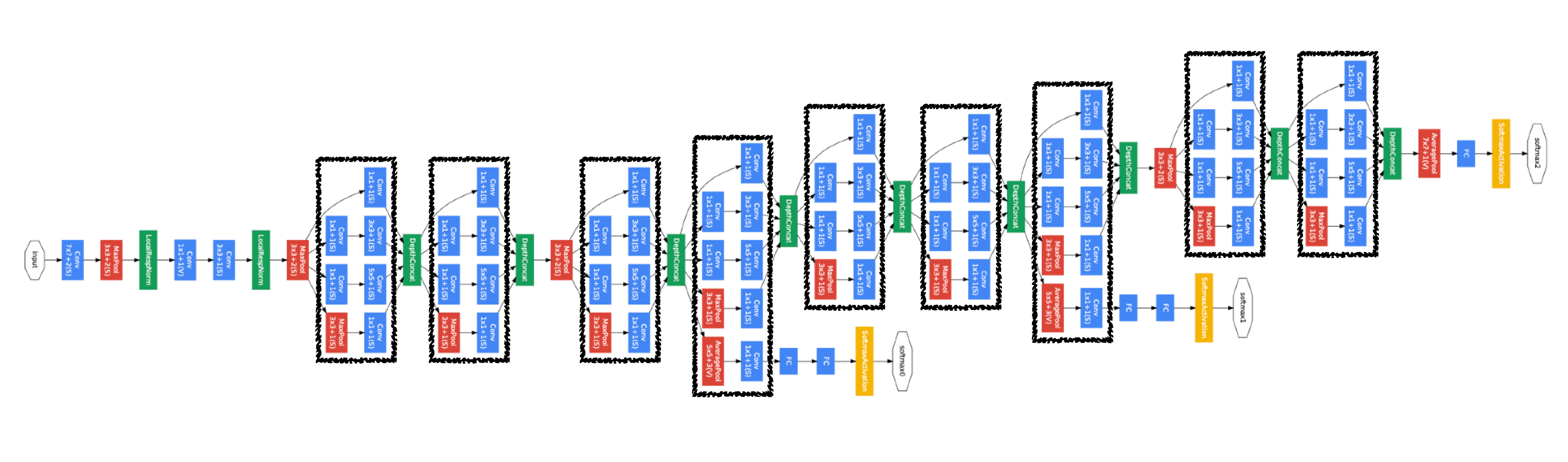
\ 의의
1. Inception block을 사용
1*1 conv block을 사용하여 parameter를 줄이는 효과가 있음
(채널수를 줄임으로써 param수가 줄어듬)
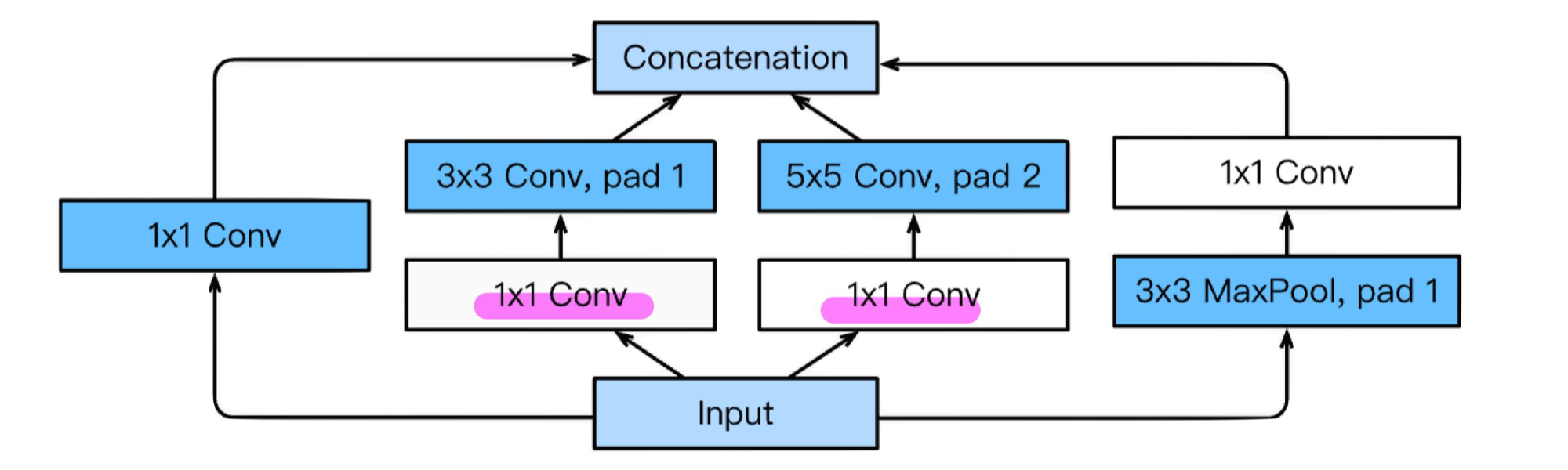
class Inception(nn.Module): def __init__(self, input_channels, n1x1, n3x3_reduce, n3x3, n5x5_reduce, n5x5, pool_proj): super().__init__() #1x1conv branch self.b1 = nn.Conv2d(input_channels, n1x1, kernel_size=1), #1x1conv -> 3x3conv branch self.b2 = nn.Sequential( nn.Conv2d(input_channels, n3x3_reduce, kernel_size=1), nn.Conv2d(n3x3_reduce, n3x3, kernel_size=3, padding=1), ) #1x1conv -> 5x5conv branc self.b3 = nn.Sequential( nn.Conv2d(input_channels, n5x5_reduce, kernel_size=1), nn.Conv2d(n5x5_reduce, n5x5, kernel_size=5, padding=2), ) #3x3pooling -> 1x1conv #same conv self.b4 = nn.Sequential( nn.MaxPool2d(3, stride=1, padding=1), nn.Conv2d(input_channels, pool_proj, kernel_size=1), ) def forward(self, x): return torch.cat([self.b1(x), self.b2(x), self.b3(x), self.b4(x)], dim=1)ResNet
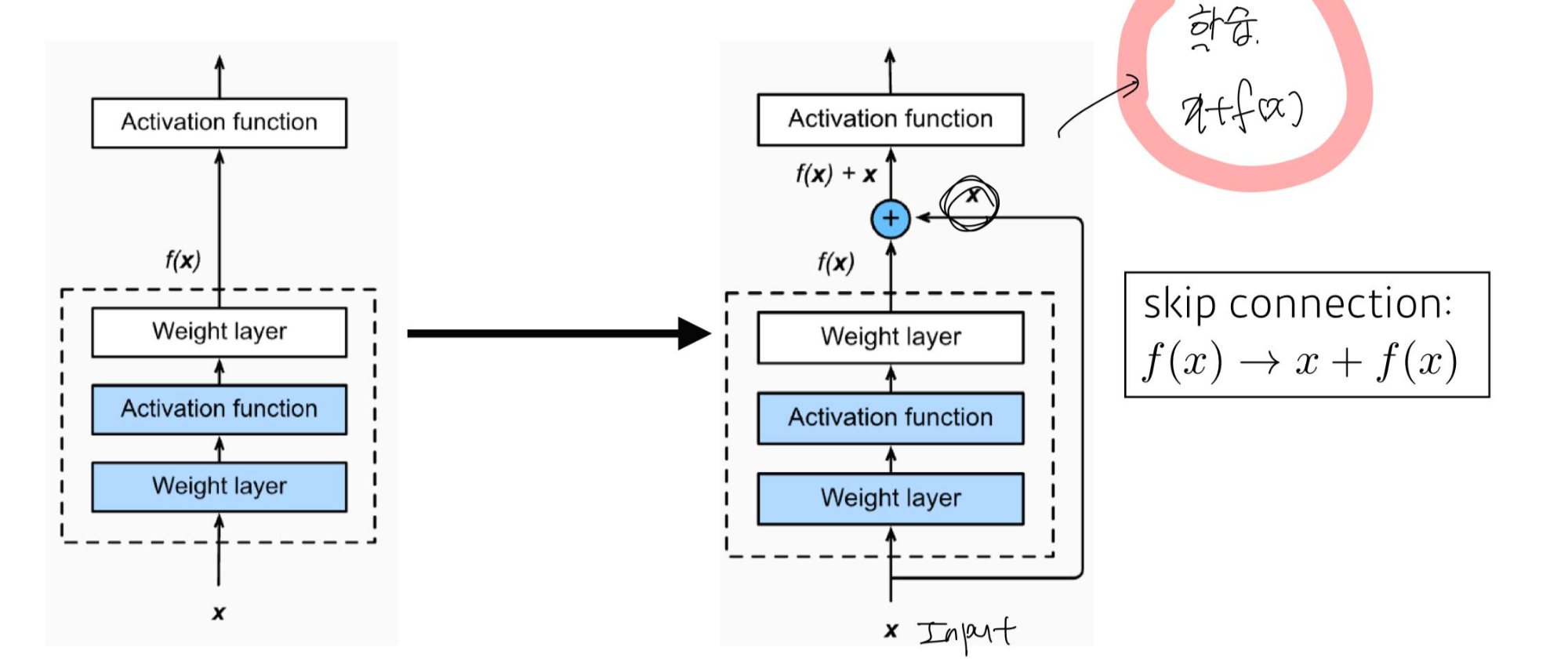
딥러닝 고질적인 문제였던 Gradient vanishing을 많이 해소하고, 깊게 쌓은 모델
의의
- skip connection을 사용함
기존과 달리 x 라는 Input이 한 block을 뛰어 넘어서 다시 input으로 활용됨.
이러한 방식은 layer로 하여금 optimal한 함수인 H(x)전체를 학습시키는 대신, 인풋을 제외한 H(x)-x를 학습하도록 함으로써, optimization 난이도를 낮춘다.
즉, H(x)-x 인 residual한 부분을 학습하도록 유도하여 residual block이라고 부른다.
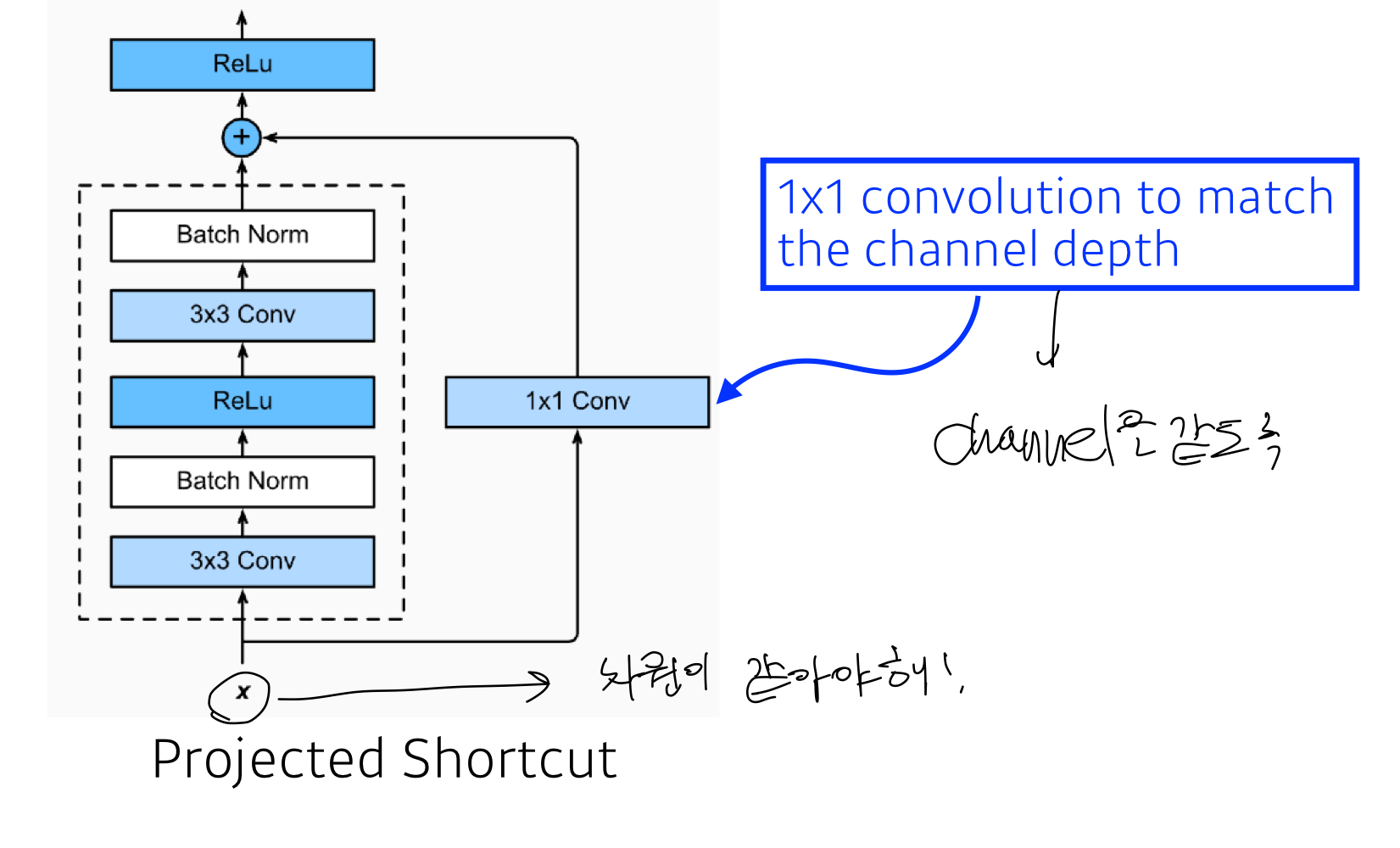
여기서도 또한 size를 맞춰주기 위해 1*1 conv를 사용한다. class BasicBlock(nn.Module): def __init__(self, in_channels, out_channels, stride=1): super().__init__() #residual function self.residual_function = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels * BasicBlock.expansion) ) #shortcut self.shortcut = nn.Sequential() #the shortcut output dimension is not the same with residual function #use 1*1 convolution to match the dimension if stride != 1 or in_channels != BasicBlock.expansion * out_channels: self.shortcut = nn.Sequential( nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(out_channels * BasicBlock.expansion) ) def forward(self, x): return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))DenseNet
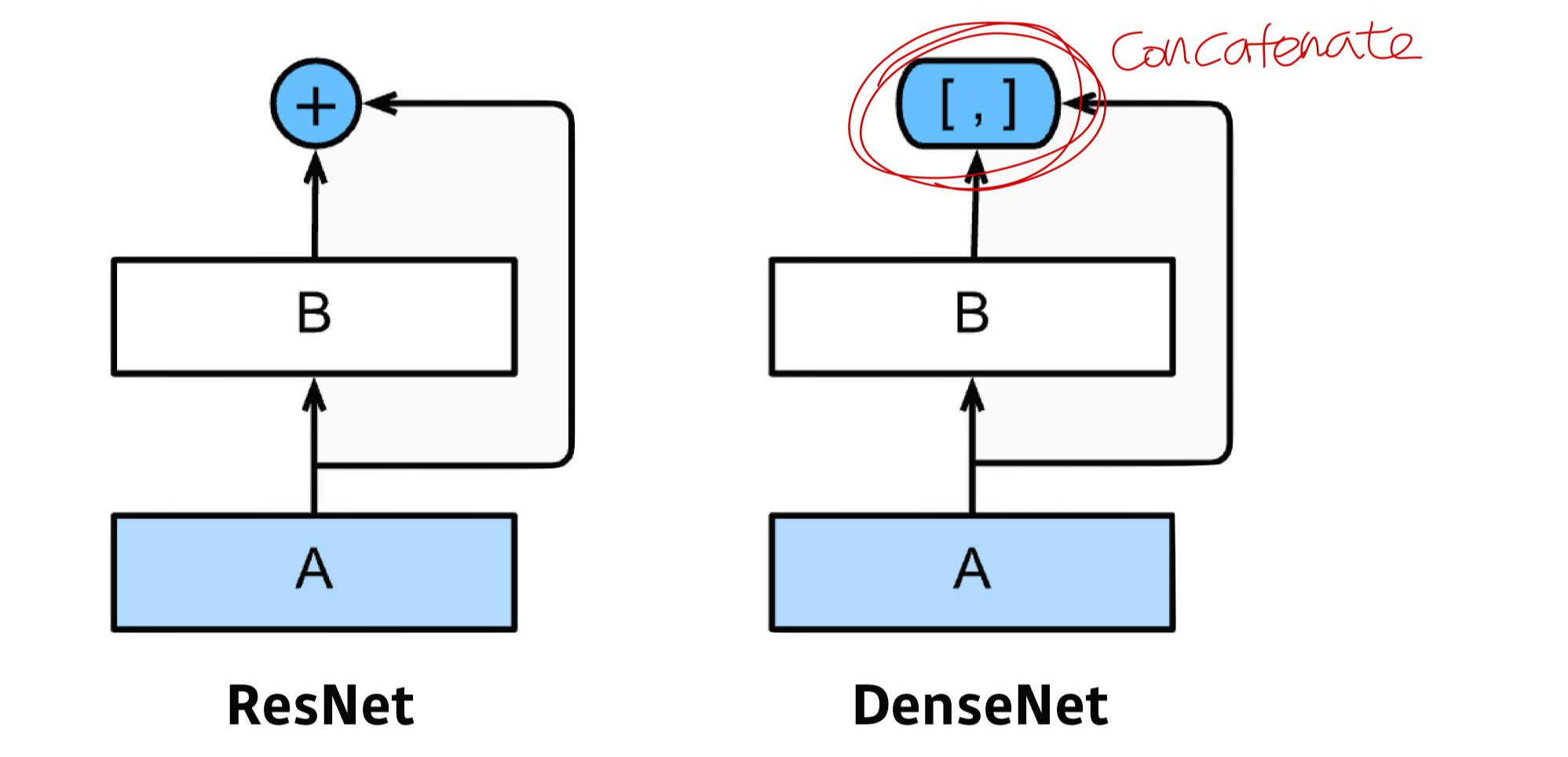
ResNet과 같지만, Input을 concatenate하여 데이터 특성을 더 보존했다.
의의
1. concatenate를 통한 의미 보존
2. 사이즈가 너무 커지는 것을 막기위한 pooling layer (transition block)을 활용

class SingleLayer(nn.Module): def __init__(self, nChannels, growthRate): super(SingleLayer, self).__init__() self.bn1 = nn.BatchNorm2d(nChannels) self.conv1 = nn.Conv2d(nChannels, growthRate, kernel_size=3, padding=1, bias=False) def forward(self, x): out = self.conv1(F.relu(self.bn1(x))) out = torch.cat((x, out), 1) return out class Transition(nn.Module): def __init__(self, nChannels, nOutChannels): super(Transition, self).__init__() self.bn1 = nn.BatchNorm2d(nChannels) self.conv1 = nn.Conv2d(nChannels, nOutChannels, kernel_size=1, bias=False) def forward(self, x): out = self.conv1(F.relu(self.bn1(x))) out = F.avg_pool2d(out, 2) return out class DenseNet(nn.Module): def __init__(self, growthRate, depth, reduction, nClasses, bottleneck): super(DenseNet, self).__init__() nDenseBlocks = (depth-4) // 3 nChannels = 2*growthRate self.conv1 = nn.Conv2d(3, nChannels, kernel_size=3, padding=1, bias=False) self.dense1 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck) nChannels += nDenseBlocks*growthRate nOutChannels = int(math.floor(nChannels*reduction)) self.trans1 = Transition(nChannels, nOutChannels) def _make_dense(self, nChannels, growthRate, nDenseBlocks, bottleneck): layers = [] for i in range(int(nDenseBlocks)) layers.append(SingleLayer(nChannels, growthRate))#concatenate nChannels += growthRate return nn.Sequential(*layers)
Segmentation
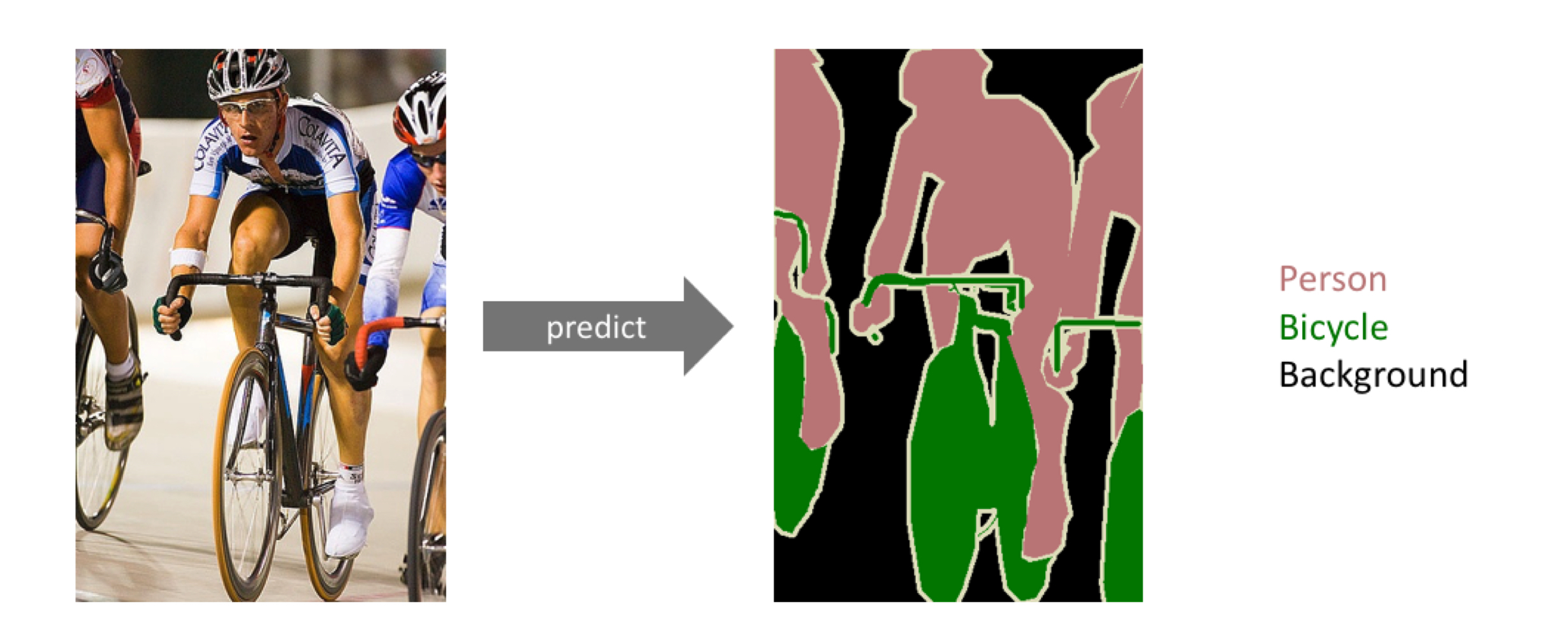
segmentation
이미지 내의 하나 하나에 대한 을 분류
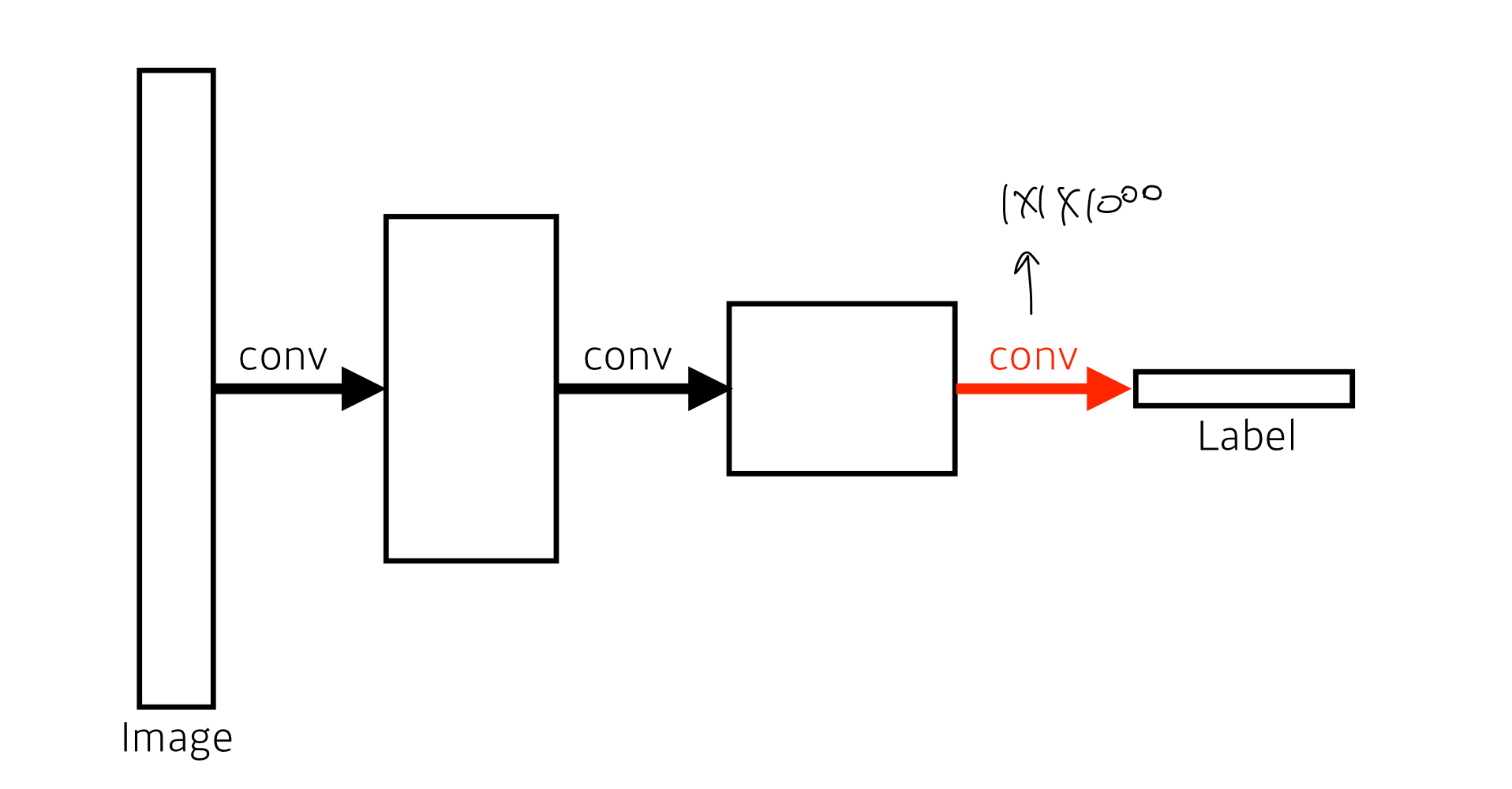
Fully Convolution Network (FCN)
deconvolution
Detection
detection
RCNN
SPPNet
Fast R-CNN
Faster RCNN
YOLO
실습
다 읽고싶다 논문..
나도 재현해보고싶다..🌸 다음주..?
gaussian37.github.io/dl-concept-global_average_pooling/
Global Average Pooling 이란
gaussian37's blog
gaussian37.github.io
'AI 부캠' 카테고리의 다른 글
[부캠]Genreative model (0) 2021.02.13 [부캠] Sequential model (0) 2021.02.05 [부캠] CNN 첫걸음 (0) 2021.02.03 [부캠] Ensemble & Optimizer & Regularization (0) 2021.02.03 [부캠] 베이즈 통계학 맛보기 (0) 2021.02.01