-
0526 - attention mask 내용 추가사과나무심기 2024. 5. 26. 23:12
https://life-of-h2i.tistory.com/117
에 내용 추가
0523 - attention mask
attention mask 가 어떻게 작용하는지 간단히 확인 ok softmax가 0이 되서 padding 에 attention이 걸리지 않는건 이해가 된다.
life-of-h2i.tistory.com
attention mask 를 이야기하기 전에
transformers 의 매우 간단한 이야기부터
Q,K,V
로 각 쿼리의 attention 을 정하는데,
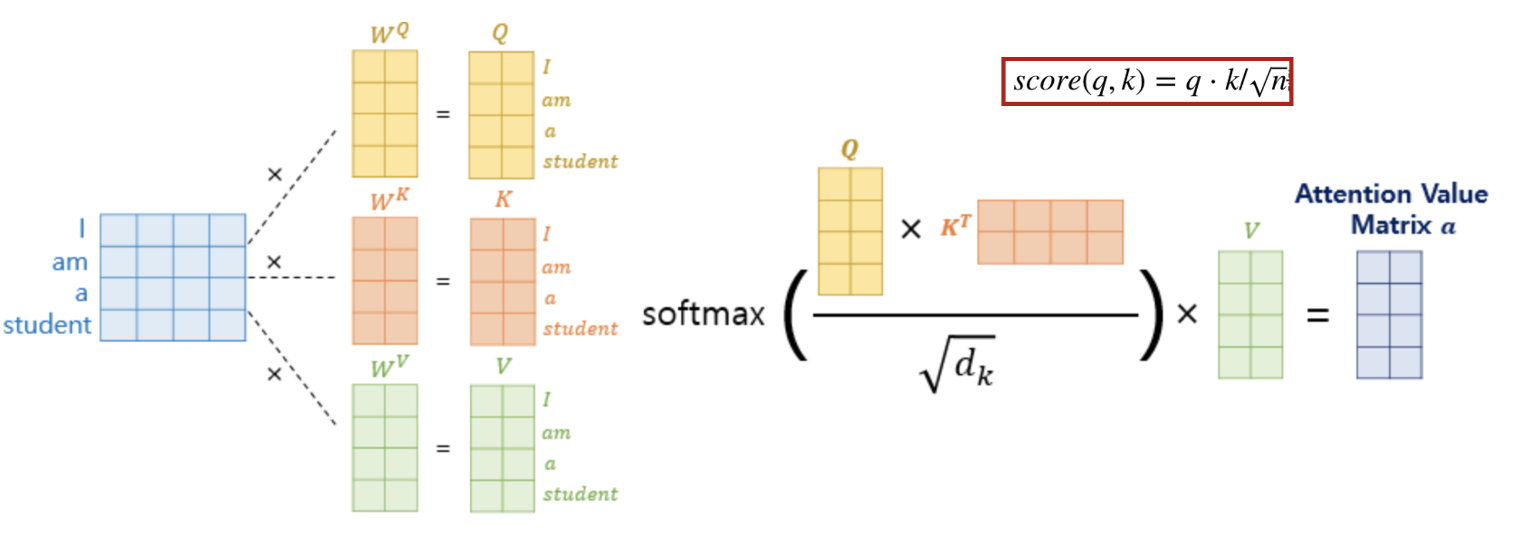
여기서 Q*K(T) 가 의미하는 것은
attention energy 라고 표현할 수 있다.
각 토큰(단어)가 서로 어느정도의 attention을 갖고 있는지가 표현된다.
*그래서 seq_len * seq_len값이 나옴.
암튼 여기에 V를 내적함으로써,
attention matrix가 나오는 것인데..
V내적 전에 attention_mask가 처리된다.


QK(T)값을 element wise로 mask matrix와 곱한다.
(여기서, mask == True이면 작은 음수값이 곱해짐.)
곱해지는지 더해지는지는 몰겟따.

attention score matrix (attention energy)에서
<pad>값에 대해 굉장히 작은 음수값으로 대체한다.
그러면, 여기에 softmax를 씌우면,
0이 된다.
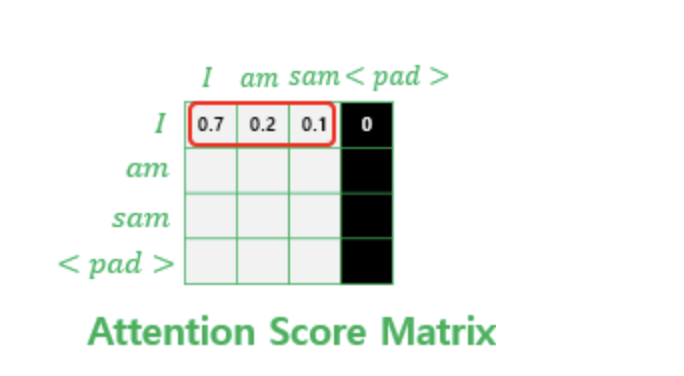
이러면 pad에 대한 attention이 걸리지 않게 될 수 있다.
다만,,!
decoder only model에 대해서
generate을 위한 attention 은 <pad>에 걸린 attention...?
(내 생각에는 결국 </s>와 같아지지 않을까 싶은데..?)
크흠..
석연찮은 부분이 있다.
decoder only부분에 대해서,
prompt learning을 하려면 prompt 들이 transformers를 통과하고,
이걸 input으로 new token이 generate되는데..
이게 prompt seq_len * V dimension이 input으로 작용하는건가?
encoder-decoder 구조에서
encoder value가 어떻게 decoder에 들어가는지 보면 될것 같다.
확인해보자
'사과나무심기' 카테고리의 다른 글
0529 - 아침보고 (0) 2024.05.29 0527 1000명의 사람을 스승으로 삼다 (0) 2024.05.28 0525 아침보고 (0) 2024.05.25 0524질문하는 방법 (0) 2024.05.25 0523 - attention mask (0) 2024.05.24