사과나무심기
0513 - Tokenizer (BPE)
리하이
2024. 5. 13. 23:15
일하다 모르는 개념들을
집에서 조금씩 다지는거? 매우 괜찮네
일할때는 듀데잇도 있고,
뭔가 원론적인 내용들을 머리에 잘 안들어오는데
집에서 차분히 보니 쉽게 들어오는구만.
(회사에서 애매하게 알고 있던것을 지금 공부한다는 말을 돌려돌려말한것임)
1. BPE (Bytepair Encoding)
BPE는 사실 압축기법이다.
가장 많이 반복되는 character-pair (2개)를 선택한다. ("aa")
aaabdaaabac"aa"를 Z로 치환한다.
ZabdZabac
Z=aa그다음 자주나오는 character-pair를 선택한다. (ab)
치환한다.
ZYdZYac
Y=ab
Z=aa이걸 더이상 치환할게 없을 때까지 반복하는 로직이다.
매우 간단하고, 직관적이다.
이걸 자연어처리에서 사용할때는 다음과 같다.
Training data vocab(BPE에 사용할 텍스트 시퀀스)를 준비하고,
byte-pair 빈도수를 기준으로 자른다.
Input이 들어오면, BPE토크나이징 기준으로 단어를 쪼갠다.
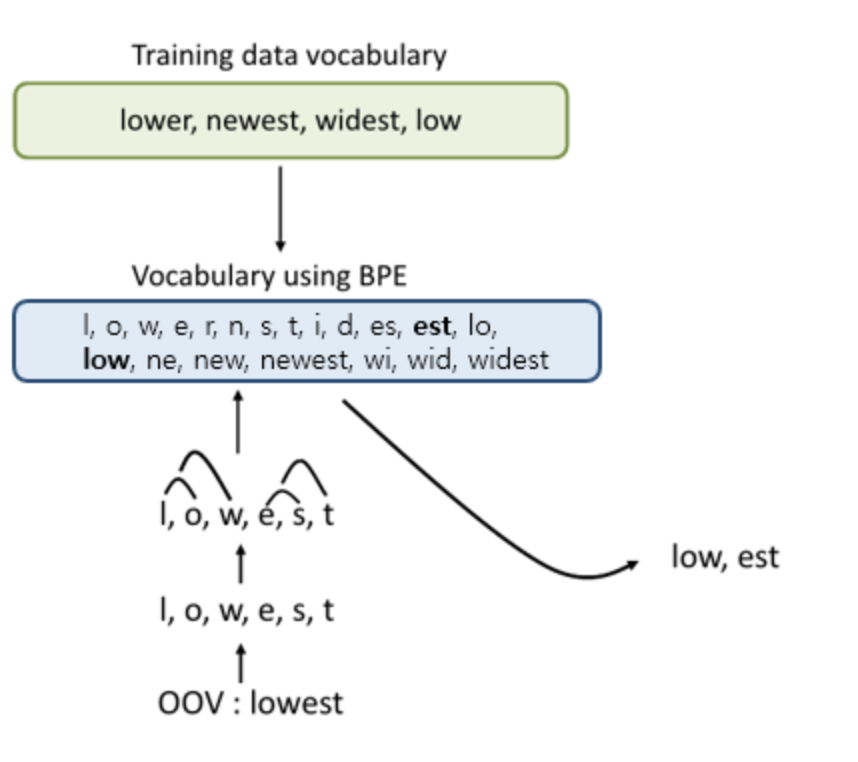
내가 궁금한 부분은 BPE encoding부분이다.
어떤 단어가 들어왔을때 그냥 greedy하게 단어를 tokenize하진 않을것이다. 그럼 어떻게 할것인가?
def get_pairs(word):
"""Return set of symbol pairs in a word.
Word is represented as a tuple of symbols (symbols being variable-length strings).
"""
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
def encode(orig):
"""Encode word based on list of BPE merge operations, which are applied consecutively"""
word = tuple(orig) + ('</w>',)
display(Markdown("__word split into characters:__ <tt>{}</tt>".format(word)))
pairs = get_pairs(word)
if not pairs:
return orig
iteration = 0
while True:
iteration += 1
display(Markdown("__Iteration {}:__".format(iteration)))
print("bigrams in the word: {}".format(pairs))
bigram = min(pairs, key = lambda pair: bpe_codes.get(pair, float('inf')))
print("candidate for merging: {}".format(bigram))
if bigram not in bpe_codes:
display(Markdown("__Candidate not in BPE merges, algorithm stops.__"))
break
first, second = bigram
new_word = []
i = 0
while i < len(word):
try:
j = word.index(first, i)
new_word.extend(word[i:j])
i = j
except:
new_word.extend(word[i:])
break
if word[i] == first and i < len(word)-1 and word[i+1] == second:
new_word.append(first+second)
i += 2
else:
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word
print("word after merging: {}".format(word))
if len(word) == 1:
break
else:
pairs = get_pairs(word)
# 특별 토큰인 </w>는 출력하지 않는다.
if word[-1] == '</w>':
word = word[:-1]
elif word[-1].endswith('</w>'):
word = word[:-1] + (word[-1].replace('</w>',''),)
return word
아하 !
일단 단어가 들어오면 그걸 다- 캐릭터로 쪼갠다음에 byte-pair로 묶는다(2개씩 묶는다)
BPE vocab에 들어있으면, 치환하고,
다시 묶고, 치환하고 이걸 반복한다.
word split into characters: ('l', 'o', 'k', 'i', '')
Iteration 1:
bigrams in the word: {('i', '</w>'), ('o', 'k'), ('l', 'o'), ('k', 'i')}
candidate for merging: ('l', 'o')
word after merging: ('lo', 'k', 'i', '</w>')
Iteration 2:
bigrams in the word: {('i', '</w>'), ('k', 'i'), ('lo', 'k')}
candidate for merging: ('i', '</w>')
Candidate not in BPE merges, algorithm stops.
('lo', 'k', 'i')
BPE는 병합 규칙도 저장해둔다. (왜?)