-
InterVL -논문 리뷰논문리뷰 2024. 4. 11. 22:47
Intern VL 의 가장 큰 contribution
- Vision Encoder를 충분히 키우면, 성능이 올라간다.
As-is : 0.3B CLIP ..
To-be : 6B Vision Encoder (Intern Vit 6B)
InterVL 의 기본 구조
InterViT (VisionEncoder) + QLLAMA (Language middleware) + LLM (Language model)
InternVit : 크기가 커진 비젼인코더
QLLAMA : LLAMA에 Vision Encoder의 임베딩벡터를 96개의 쿼리로 cross attention하는 레이어 1B를 포함한 모델 (Qformer의 42배)
LLM : 기존 오픈된 모든 llm 사용 가능 (여기선 Vicuna 13B)

Swiss army knife model라고 말하는데,, 그냥 필요에 의해 꼈다 뺏다 할수 있음! 조합가능!

1) classification task : Intern vit only (Feature map H/14 * W/14* D -> avg pooling -> linear)
2) Contrastive task : InternVL-C or InternVL-G (어디서 attention pooling을 하는지가 다름)
3) Generative task : InternVit + QLLAMA 로 캡션 생성 가능 (QLLAMA가 충분히 scaleup되어있어 가능)
4) multi-modal dialogue : InternViT + QLLAMA(optional) + LLM
어떻게 큰 Vision Encoder 와 LLM을 align 했는가? (학습방법)
stage 1) Contrastive learning
- model : intern VIT (trainable) + LLAMA 7B (trainable)
- loss : cross entropy (CLIP)
- dataset : LAION-en, LAION-multi, LAION-COCO, COYO, Wukong (6.03B ->(cleaning)->4.98B)
2) Generative learning
- model : intern VIT (frozen) + QLLAMA ( cross attenction, query :trainable / llama 7b : frozen)
- loss : BLIP loss function ( ITC, ITM, ITG)
- dataset : LAION-en, LAION-multi, LAION-COCO, COYO, Wukong (caption filtering 4.98B -> 1.03B)
3) Finetuning
multi-modal dialogue system등을 위한 튜닝
* QLLAMA 와 LLM의 feature space가 유사
- model : MLP(trainable)로 intern vit feature(frozen), qllama feature (frozen)를 LLM에 transfer
실험 정리
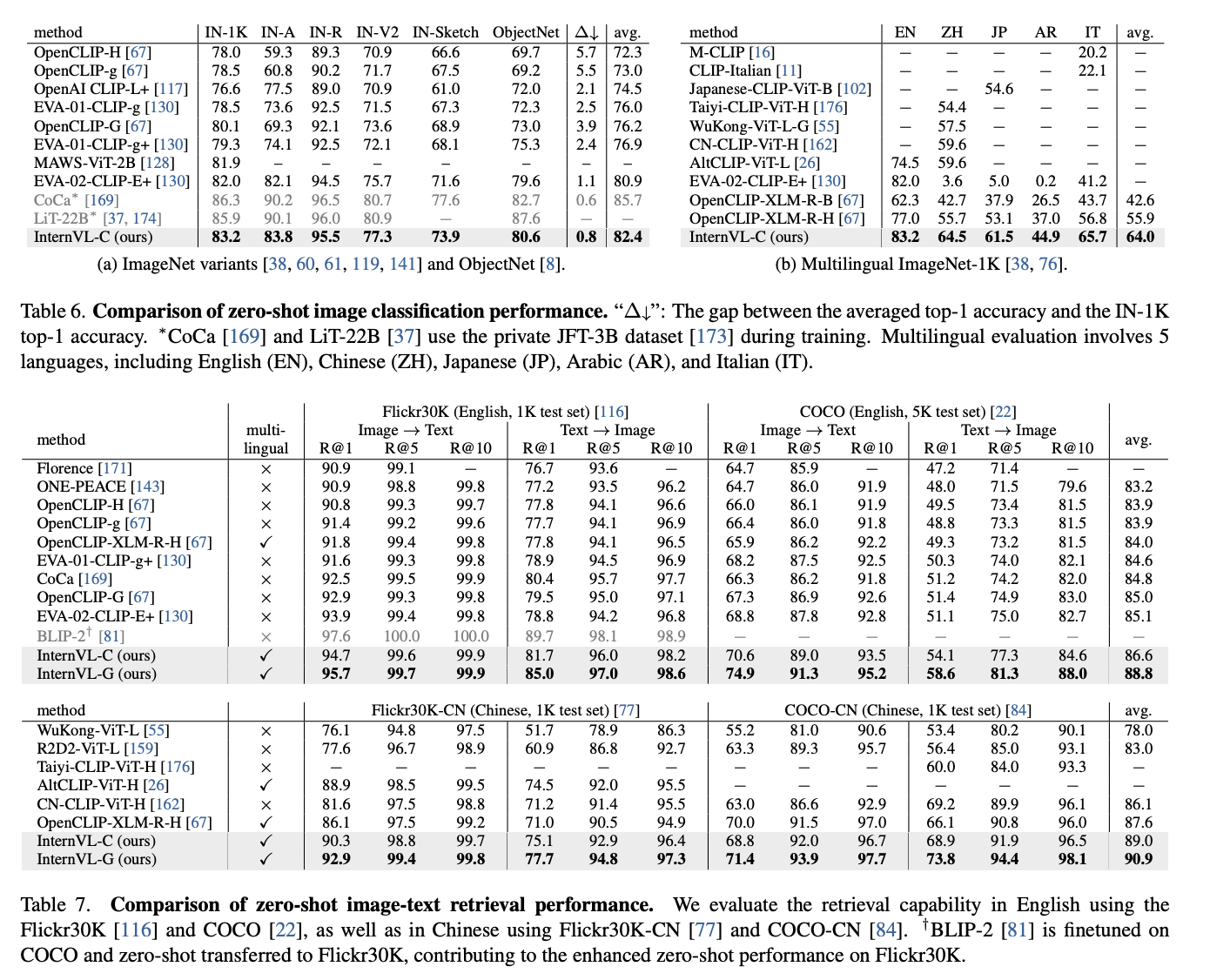
- EXP1> Image classification
- model : InternVL-C
- dataset : multilingual ImageNet 1K
- EXP2>Video Classification (single frame setting)
- model : InternVL-C
- dataset : Kinetics-400/600/700
- EXP3> Image-Text Retrieval
- model : InternVL-C, InternVL-G
- dataset : Flickr30K, COCO
- result : InternVL-G에서 좋은 성능 -> QLLAMA의 query로부터 나온 visual feature가 더 align이 잘 맞음
- EXP4> Image caption
- model : InternVL-G (with Vicuna 13B)
- dataset : Flickr30K, COCO
- result : InternVL-G에서 좋은 성능 -> QLLAMA의 query로부터 나온 visual feature가 더 align이 잘 맞음
Cross attention
Qllama code 살펴보기
'논문리뷰' 카테고리의 다른 글
Sequence Parallelism: Long Sequence Training fromSystem Perspective (0) 2022.10.10 Style Gan 리뷰 (0) 2021.02.13 Semi-supervised learning - Fix match (1) 2020.08.02 [논문리뷰]Unsupervised Out-of-Distribution Detection by Maximum Classifier Discrepancy (0) 2020.06.13