-
[부캠]NLP 05 (NLP pre-trained model)AI 부캠 2021. 2. 21. 21:18
- Self supervised pretraining model
- GPT-1
- BERT
- GPT-2
- GPT-3
- ALBERT
- ELECTRA
- Light-weight Models
- Fusing Knowledge Graph into Language Model
Self supervised pretraining models
딥러닝 모델에는 supervised model과 unsupervised model이 있다.
supervised model은 특정한 label이 있어서 그것을 맞추는 문제 ex) classification
unsupervised model은 label이 없이 거리, 밀도 등 데이터에서 얻을 수 있는 특징으로 푸는 문제 ex) clustering
Self supervised model은 그 중간에 존재한다.
supervised model 이지만, label이 있는 것이 아니라, 자신(model)이 직접 label을 만들어서 그 label에 따라서 학습을 한다.
그래서, self supervised model은 크게 2가지로 나눠진다.
1. 문제 정의 : 어떤 문제를 생성해서 풀것인가?
2. 모델 : 그 문제를 어떤 모델을 이용해 풀것인가?
비젼에서 직관적인 예를 보자.
예를 들어 self supervised model은 이미지에 대해 random으로 회전(0,90,180,270)을 시키고,
스스로 이미지가 몇도 회전했는지를 맞추면서 이미지에 대해 학습을 한다.

Self supervised에서는 이렇게 스스로 문제를 만들고 풀면서 Dataset에 대한 context를 이해할 수 있다.
이를 pretrain model이라고 하고, 우리가 진짜 원하는 task(downstream task)에 대해 최종 layer를 수정해 fine tuning 하는데 사용된다.
서론이 길었다.
아무튼, NLP task에 transformer가 도입되면서 이런 pretrain model이 많이 제안되고 있다.
(미리 좋은 GPU로 많은 데이터를 self supervised learning하고, 사용자는 fine tuning을 할 수 있게)
여러 transformer 기반의 모델을 1) 어떤 모델 구조인지 2) 어떤 self supervised learning 3) 활용되는 downstream task을 하는지 중심으로 살펴보자.
GPT-1
- special token을 도입했음
- classification task를 위해 Extract라는 special token을 도입 | 문장 끝에 삽입되어 됨
모델 구조
- 12layer decoder only transformer
- 12 head/ 786 dimensional states
- GELU activation function
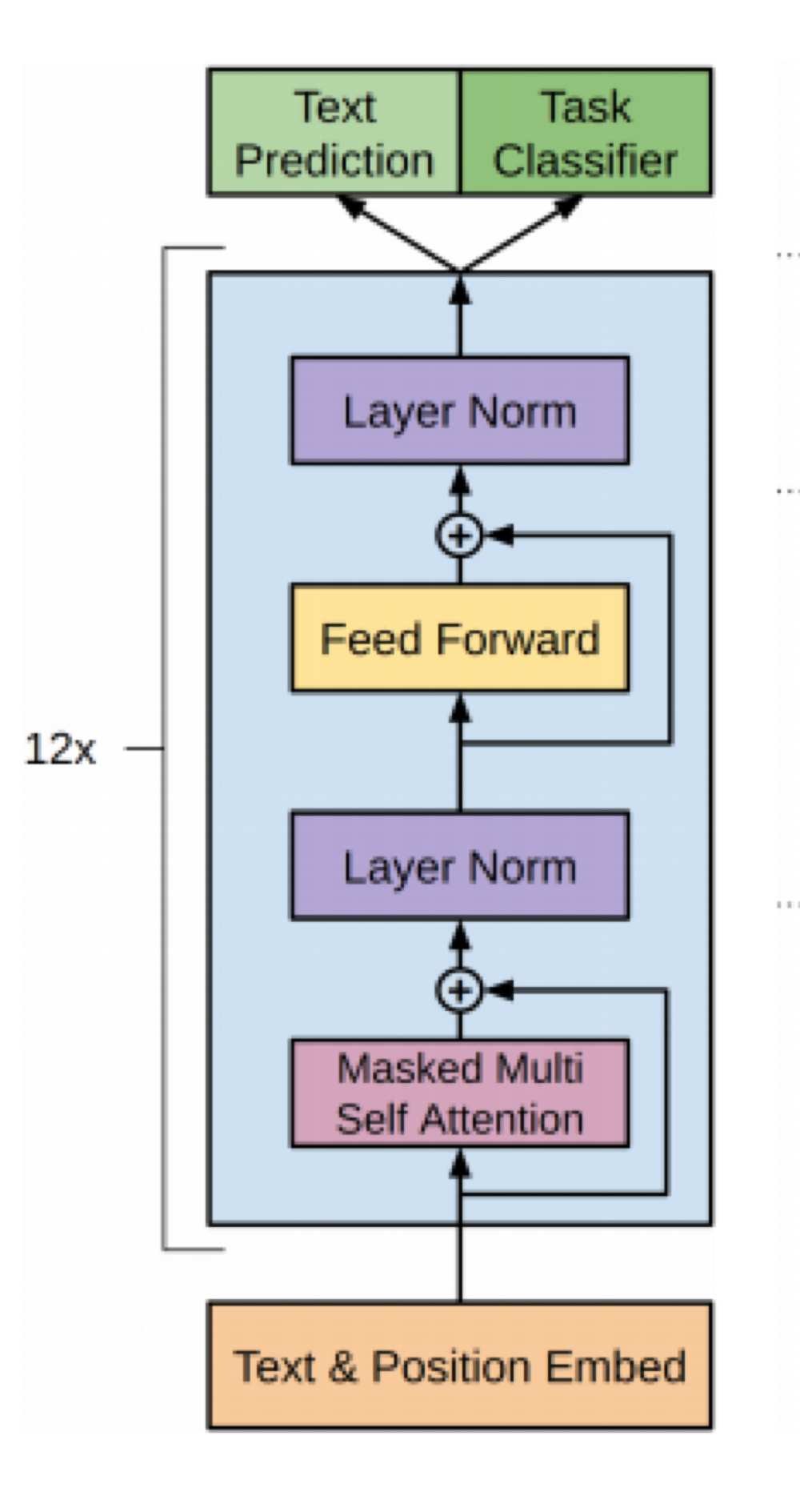
Self supervised task
다음 문장 예측
Downstream task
classification, Entailment, similarity, Multiple choice

BERT
- Bidirectional transformer
- Use large scale data & large scale model
- Wordpiece embeddings (sub word 토큰 사용 / 30000 word piece)
- learn positional embedding
- [CLS] token 사용 | classification task를 위해 이용. 문장의 앞에 삽입되어짐
- segmentation embedding 사용
- [SEP] token 사용
모델 구조
Base : layer 12, dimension 786, multi head 12
Large : layer 24, dimension 1024, multi head 16

Self supervised task
1. Masked Language Model
글의 일부를 Mask(약 15%)하고, 그 글을 맞추는 문제
*mask할 단어중 80%는 mask, 10%는 랜덤으로, 10%는 그냥 그대로 둠 --> down stream task에는 [MASK]가 없기 때문

2. Next Sentence Prediction (NSP)
Sentence 2개를 [SEP]토큰으로 묶어주고, 이 2개의 sentence가 1도큐먼트의 연속적인 문장인지(Is Next or not)을 맞추는 문제

** NSP 문제를 위해 Segmentation embedding을 추가
문장에 대한 구분이 필요하기 때문에 positional encoding과 함께 Segmentation embedding 사용

Downstream task
- Machine Reading Comprehension (MRC) : 지문을 잘 이해해서 지문안의 답을 대답하는 방식 (독해기반 Question Answering)

- 사용 데이터 set : SQuAD
- 학습 방법 : 지문과 질문은 [SEP]토큰으로 결합. BERT모델로 2개의 linear가 나오도록 함. 이 linear에서는 각각 지문에서 정답 시작 index와 끝 index를 학습함.
- upgrade : SQuAD 2.0에서는 Answering와 no Answering도 구분하도록함.
- 적적한 다음문장 찾기

- 사용 데이터 set : On SWAG
- 학습 방법 : 각 문장을 연결/ Scala 값을 뱉도록함

** GPT-1 vs BERT
<!--td {border: 1px solid #ccc;}br {mso-data-placement:same-cell;}-->
model training size token batch size task specific tuning GPT1 800M [Extract] 32000 words 5.00E-05 BERT 2500M [SEP],[CLS] 128000words
(배치가 커질수록 효과가 커짐)depend GPT-2
- GPT -1 과 비슷, 더 깊은 layer를 쌓은 구조
- 40GB text를 훈련 (reddit 커뮤니티 text 크롤링)
- zero shot setting에서도 어느정도 성능을 보여줌
- BPE (byte pair encoding)으로 input 형성
모델 구조
- Layer normalization의 위치 변화
- layer에 대한 초기 initialize를 layer의 index에 따라 다르게 줌

Self supervised task
다음 단어 예측
Downstream Task
Text Summarization : TL;DR 토큰이 있으면, summarization 수행
GPT-3
- transformer을 더더욱 깊게 쌓은 모델
- few shot learning에 탁월
*few shot learning (이미 pretrained 된 모델을 architecture변형없이 약간의 데이터로 학습)

모델 구조
- 96개 attention layer
- 175 billion parameters
Self supervised task
다음 단어 예측
ALBERT
- transformer의 많은 parmeter 수, Memory limitation을 줄여보고자 함.
- Wq,Wk,Wv,Wo 벡터의 차원을 줄임
- parameter를 공유해보고자함
- 새로운 self supervised task 제안 : sentence order prediction
모델 구조
BERT와 거의 동일한 구조
- Embedding vector를 줄임 (raw rank factorization)

- Cross layer Parameter sharing
여러개로 stack한 multi head attention model의 parameter를 공유하고자 함.

Self supervised task
Sentence Order prediction
: NSP의 경우, 서로 다른 doc에서 문장을 추출해 문제가 쉬운 경향을 보임
같은 doc에서 추출하는데, continous한지를 판단하는 방법.
ELECTRA
Self supervised task
Replaced Token Detection
: Masking 된 단어 예측 + 각 word가 original인지 replace인지 ( GAN )

Light-weight Model
transformer 계열의 model을 경량화하는 방법들이 고안되고 있다.
Distill BERT
heavy한 teacher 모델과 light한 student 모델에서
student 모델의 확률 분포가 teacher 모델의 확률 분포와 비슷하도록 학습

TinyBERT
heavy한 teacher 모델과 light한 student 모델에서
student 모델의 전반적인 weight가 teacher 모델의 전반적인 weight와 비슷하도록 학습

Fusing Knowledge Graph into Language Model
transformer모델은 주어진 문장에 대해서는 잘 파악하지만, 문장 바운더리 밖의 task는 잘 파악하지 못한다.
그래서, transformer model과 Knowledge graph (상식과 관련한 그래프)를 같이 결합해 이러한 한계를 해결하고자 한다.
eg ) ERNIE, KagNET
진짜 바빴는데, 진짜 즐거웠던 1주일이랄까🐯
'AI 부캠' 카테고리의 다른 글
[부캠] CV 01 (0) 2021.03.09 [부캠] Graph01 (0) 2021.02.22 [부캠] NLP 04 transformer model (0) 2021.02.19 [부캠] NLP03 (0) 2021.02.17 [부캠]NLP2 (0) 2021.02.16