-
- RNN
- LSTM
- GRU
RNN
RNN
Seqeuential data를 처리할 때, 과거의 정보를 다음 input과 함께 전달하는 모델.
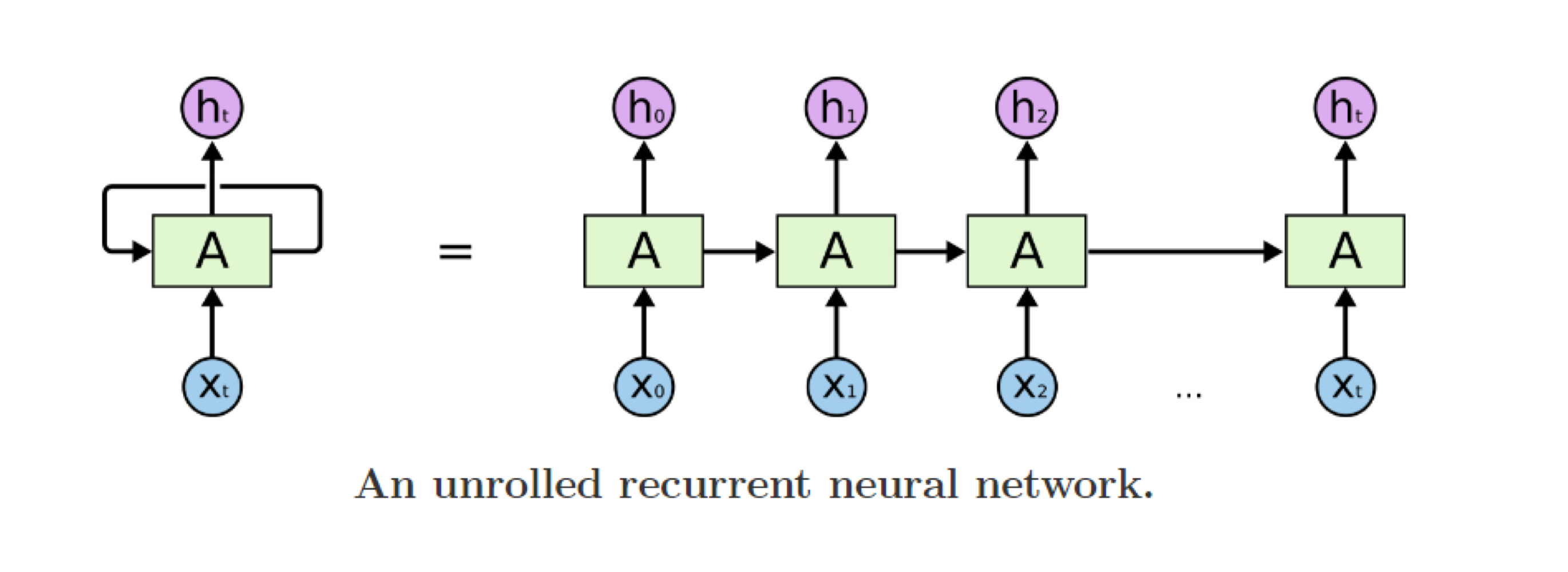
모든 time step에서 같은 parameter(weight)를 공유한다는 특징이 있다.
다음과 같이 fW라는 함수는 weight W를 갖는다.
이 W 는 ht-1 벡터에 대한 weight Whh, xt벡터에 대한 weight Wxh로 이루어져있다.
또한, 이렇게 만들어진 ht를 output 으로 만들어주는 Why도 존재한다.
여기서 핵심은 이 Whh,Wxh,Why를 모든 time step에서 공유한다는 것이다.
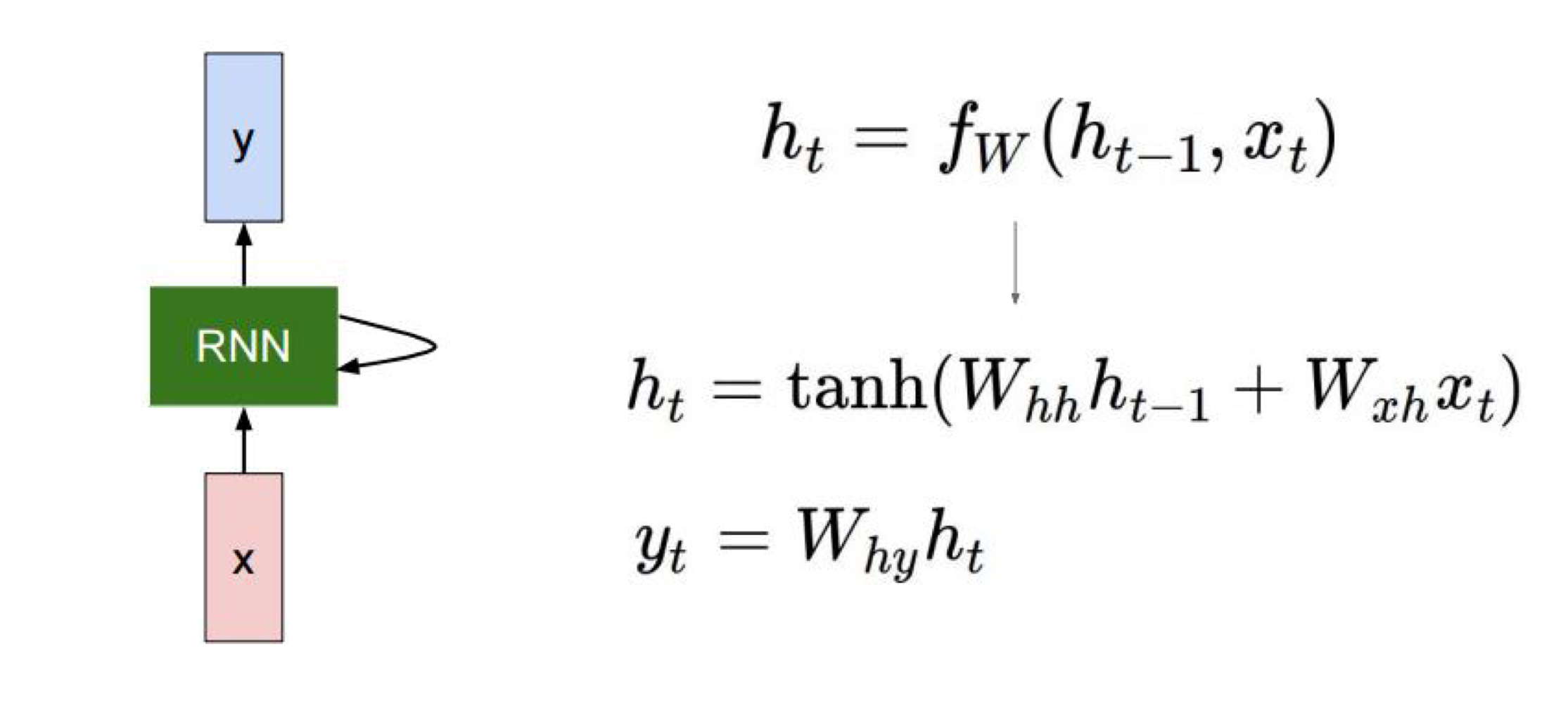
RNN families backpropagation (BPTT)
그렇다면, 어떻게 backpropagation을 진행해 학습할까?
BPTT (backpropagation through time)방식으로 backpropagation을 구한다.
즉, 모든 time step에 대해 같은 weight를 적용하여 각각 loss를 구한 뒤, 한번에 back propagation을 진행한다.
그럼 직접 backpropagation을 해보자.
그림은 우리가 아는것처럼 t시점에서의 RNN 내부의 output에 대한 backpropagation이다.
여기서 yt에 대한 loss값이 나오고, 그것에 대한 gradient를 구할 수 있다. 이것을 back propagation을 차근히 진행하였다.

여기서 RNN은 하나가 더 들어가게 되는데,
다음 time step에 들어가는 ht이다. 이것에 대해서는 제일 마지막 time step에서부터 계산된 gradient가 있을것이다.
이를 더해줘야한다.

즉,
다음과 같은 t 시점에서는 해당 t에서의 output loss값의 gradient와 제일 마지막부터 계산된 gradient가 더해진다.
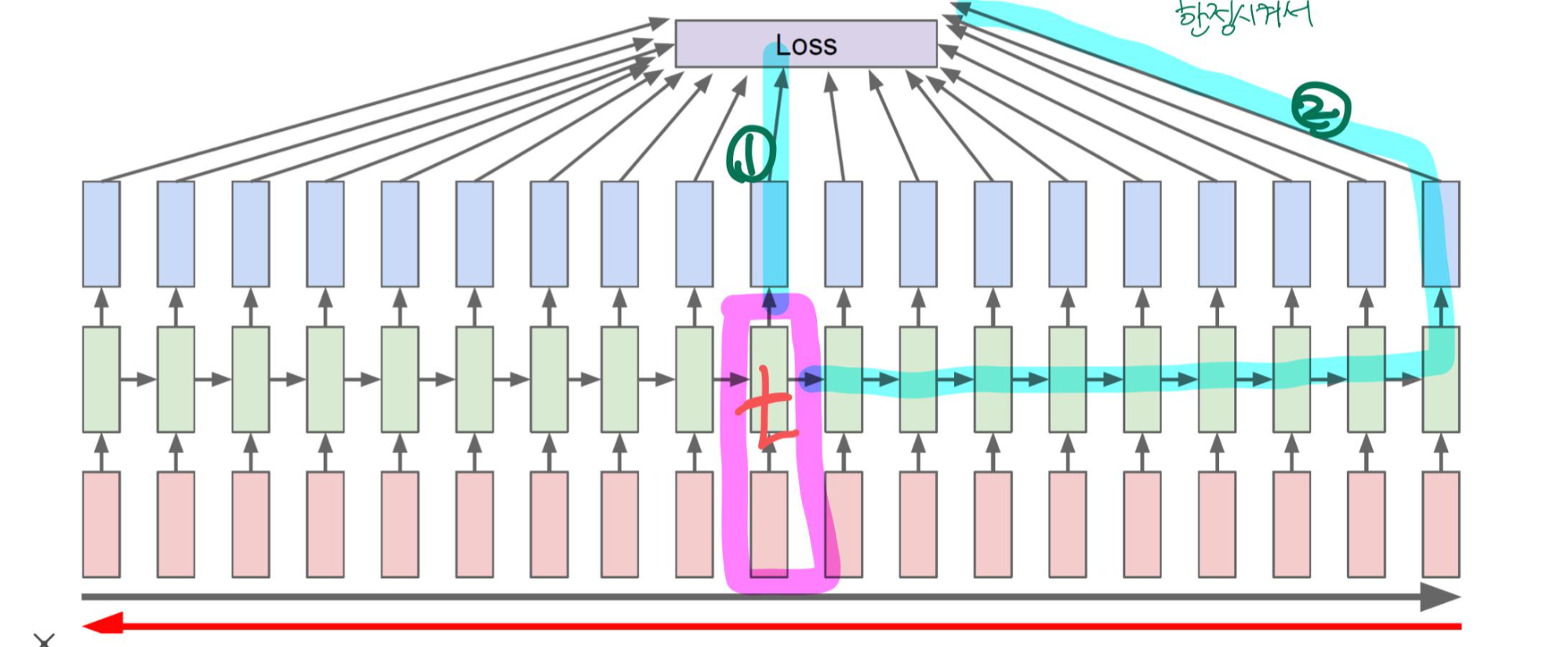
RNN task
one to many : ex> image captioning
many to one : ex> text sentimental analysis
many to many : ex> machine translation, video classification on frame level
Limitation of RNN
RNN 의 고질적(?) 필연적(?)인 한계가 있다.
1) Gradient vanishing, exploding problem
gradient가 time step 만큼 전달되는 과정에서 gradient가 너무 커지거나, 0에 수렴하는 경우가 있다.
해결(?) 방안 : clip gradient를 통해 gradient가 너무 커지는(exploding) 현상을 줄인다.
2) 초기 time step 정보 유실
Sequence 길이가 길어지면, 과거의 정보를 갖고 있는 ht에는 초기 time step의 정보가 많이 유실 될 수 밖에 없다.
(계속 tanh로 값을 바꾸기 때문에..)
해결(?) 방안 : LSTM, GRU, attention model
RNN 실습
*초기 히든벡터(모든 값이 0으로 채워진 벡터)를 전달해야한다.
*참고로, RNN계열의 input값은 Batch_size*lenght*embedding 이 아니라, lenght*batch_szie*embedding 형태이다.
*우리가 익숙한 Batch_size*length*embedding으로 하려면, batch_first = True를 rnn모델에 지정해줘야한다.
hidden_size = 512 # RNN의 hidden size num_layers = 1 # 쌓을 RNN layer의 개수 num_dirs = 1 # 1: 단방향 RNN, 2: 양방향 RNN rnn = nn.RNN( input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, bidirectional=True if num_dirs > 1 else False ) """ # ""batch_first = True rnn = nn.RNN( input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, bidirectional=True if num_dirs > 1 else False, batch_first = True ) """ h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (num_layers * num_dirs, B, d_h) hidden_states, h_n = rnn(batch_emb.transpose(0, 1), h_0) # d_h: hidden size, num_layers: layer 개수, num_dirs: 방향의 개수 print(hidden_states.shape) # (L, B, d_h) print(h_n.shape) # (num_layers*num_dirs, B, d_h) = (1, B, d_h)LSTM
LSTM
가장 핵심적인 아이디어는 gate 를 통해 어떤 변환(transformation)없이 과거의 정보를 전달하자! 이다.
LSTM은 h 벡터 뿐만아니라, c 벡터 또한 가지고 있다.
ht 벡터는 현재 t에서의 output을 내기위한 정보가 담겨져있고,
ct 벡터는 현재 t까지 기억해야할 필요가있는 정보가 담겨져있다.
LSTM은 4개의 gate가 존재한다.
- i : input gate
- f : forget gate
- o : ouput gate
- g : gate gate
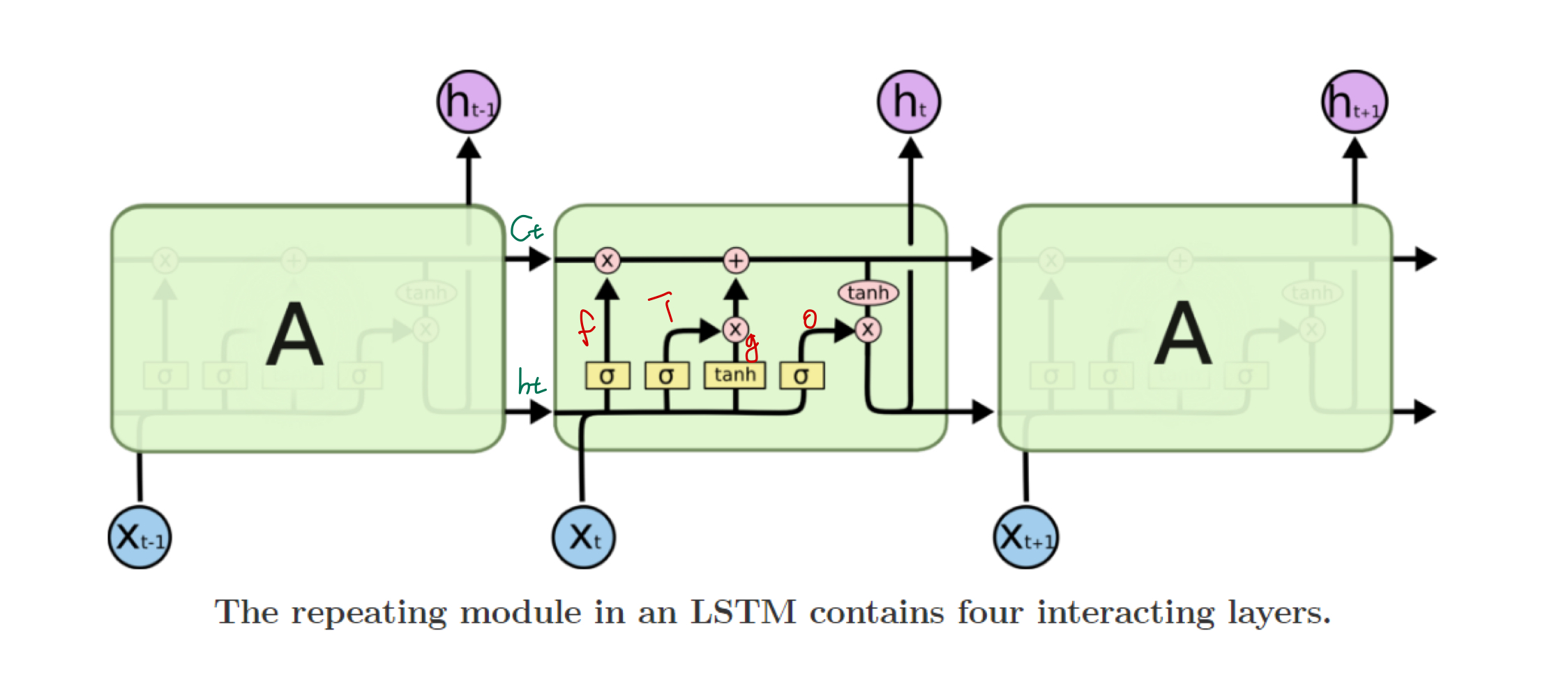
하나씩 살펴보자.
1.
처음에 Ct-1, ht-1, Xt 인풋이 들어오면,
ht-1, Xt를 이용해 forget 게이트에서 Ct-1 대해 얼만큼 forget할지를 정한다.
얼만큼 forget할지 0~1사이의 비율로 구해야하기 때문에, sigmoid activation function을 통과시켜준다.
이 벡터를 forget vector 라고 한다.

2.
input gate에서는 현재 들어온 ht-1, X에 대해 얼만큼 저장할지를 결정한다.
그리고 gate gate를 이용해서 ht-1, X에 대해 의미 있는 값을 저장한다.
input gate에서 나온 Input vector와 gate gate에서 나온 gate vector를 곱해서, 다음 time step으로 전달할 값을 구한다.

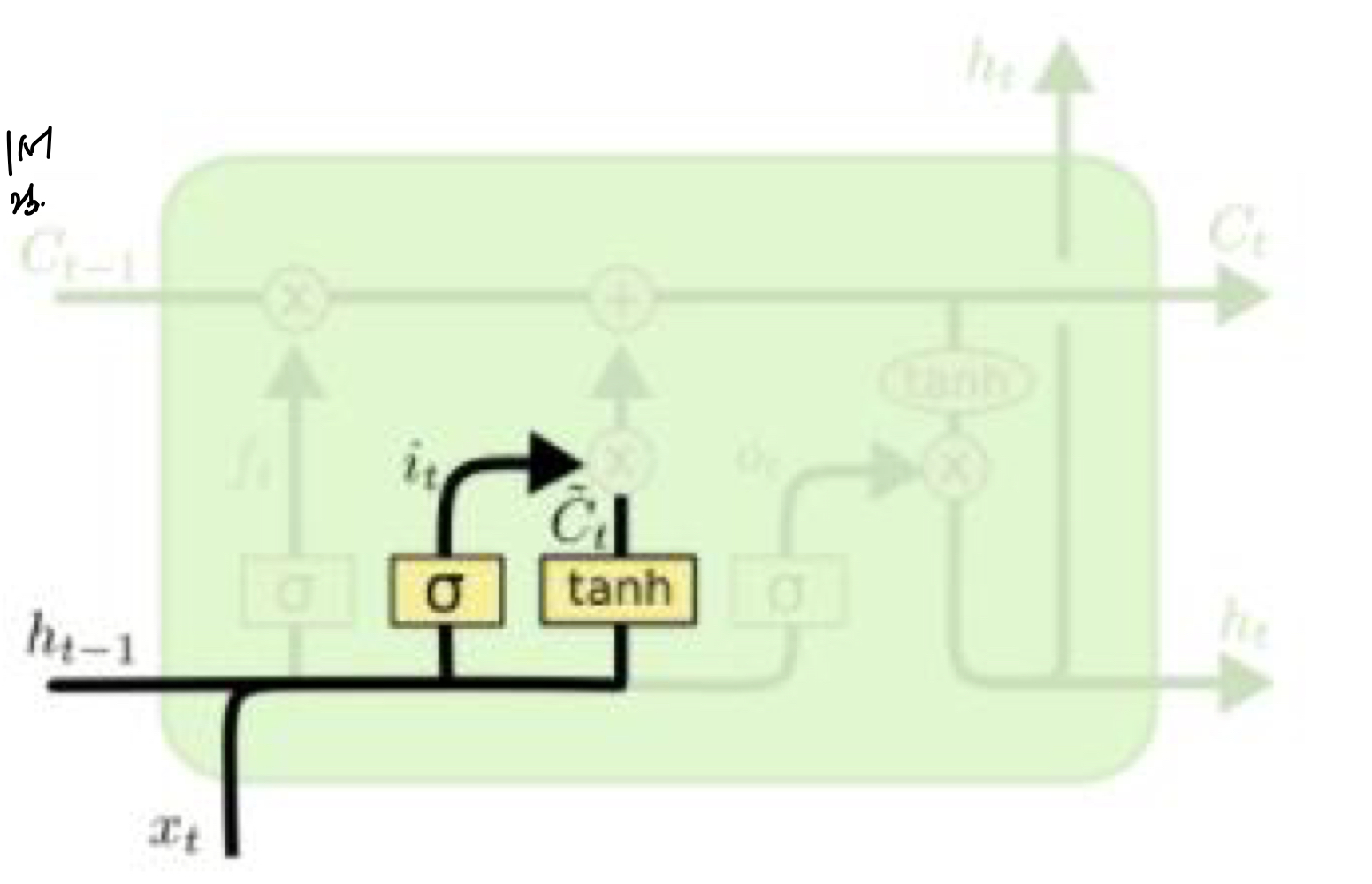
3.
1에서 구한 Ct-1에 forget vector를 곱한 값과 2에서 구한 input vector 와 gate vector를 곱한 값으로 새로운 Ct 벡터를 구한다.
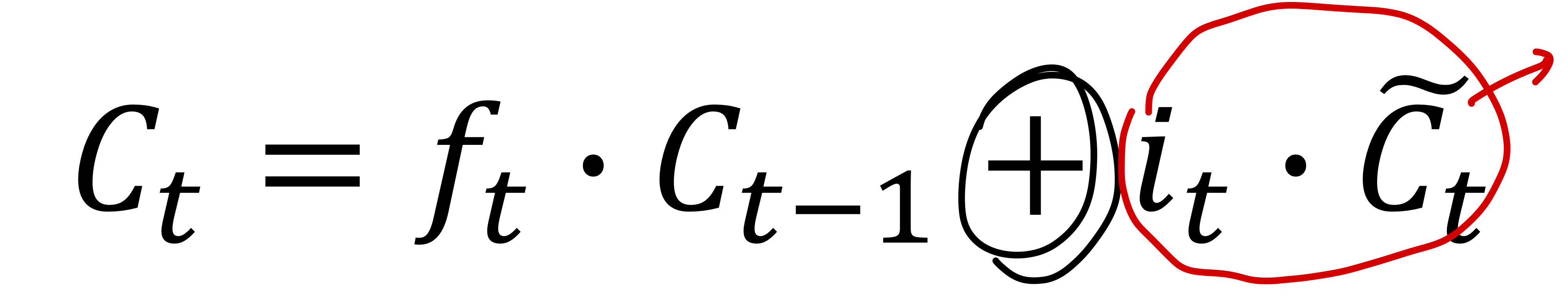
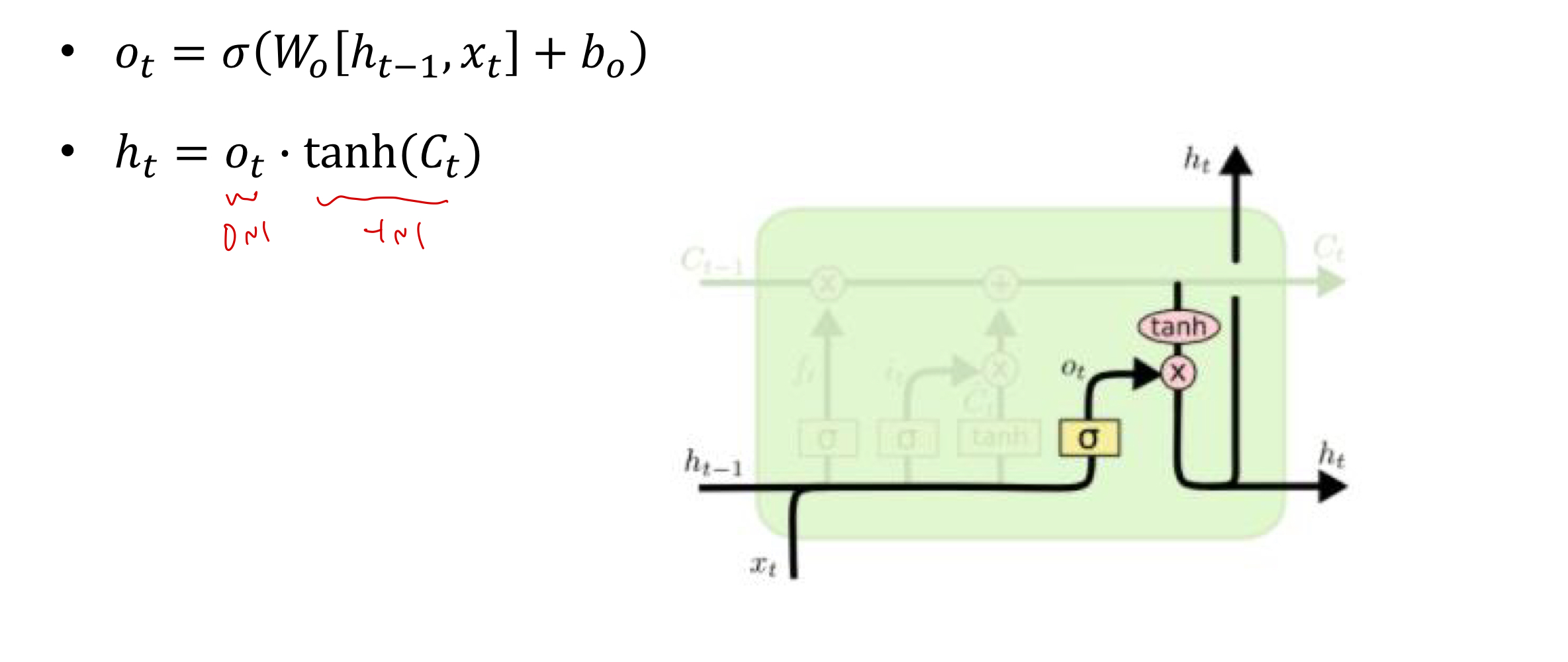
4.
마지막으로, output gate를 이용해서 output으로 내보낼 값을 구한다.
embedding_size = 256 hidden_size = 512 num_layers = 1 num_dirs = 1 embedding = nn.Embedding(vocab_size, embedding_size) lstm = nn.LSTM( input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, bidirectional=True if num_dirs > 1 else False ) h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (num_layers * num_dirs, B, d_h) c_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (num_layers * num_dirs, B, d_h) # d_w: word embedding size batch_emb = embedding(batch) # (B, L, d_w) packed_batch = pack_padded_sequence(batch_emb.transpose(0, 1), batch_lens) packed_outputs, (h_n, c_n) = lstm(packed_batch, (h_0, c_0))GRU
GRU
LSTM 보다 간단한 버전이랄까..
C state를 없애고, hidden vector가 C state 비슷한 역할을 하는 것이라 보면 된다.
forget vector 를 1-z로 대체했다!

gru = nn.GRU( input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, bidirectional=True if num_dirs > 1 else False ) output_layer = nn.Linear(hidden_size, vocab_size) input_id = batch.transpose(0, 1)[0, :] # (B) hidden = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (1, B, d_h) output, hidden = gru(input_emb, hidden) # output: (1, B, d_h), hidden: (1, B, d_h)
늘 정리가 제일 어렵다.. ㅎㅎ
'AI 부캠' 카테고리의 다른 글
[부캠] NLP 04 transformer model (0) 2021.02.19 [부캠] NLP03 (0) 2021.02.17 [부캠] NLP #1 (0) 2021.02.15 [부캠]Genreative model (0) 2021.02.13 [부캠] Sequential model (0) 2021.02.05